




亚马逊选品,不要只看BSR了

 1018
1018前言

做亚马逊选品,我们都知道一件事:真正要看的不是单个 ASIN,而是整个类目的竞争格局。
所以在搭建目标类目的 ASIN 库时,我们通常会从多个渠道去补全数据:比如参考 BSR 榜单、关键词搜索结果页、竞品关联关系等,尽可能把相关 ASIN 找全。
但这里有一个容易被忽略的问题:BSR 类目更适合做平台榜单参考,但在精细化选品分析中,可能会受到类目颗粒度、商品归类方式、卖家填报等因素影响,导致同一榜单下混入部分非强相关 ASIN。
而 ASIN 库一旦不够干净,后续反查出来的关键词、测算出来的市场体量、判断出来的竞争格局,都可能随之产生偏差。也就是说,选品判断的偏差,不一定发生在最后的分析环节,而可能从“目标类目 ASIN 库搭建”这一步就已经开始了。
真实工作流:一周多时间换一份有漏洞报告
一个典型场景
我们要分析"挂脖风扇"这个类目时,工作流通常是这样:
因为亚马逊目前没有"挂脖风扇"这个类目,我们只能退而求其次去 "Personal Fans" 里找——打开 BSR 翻 Top 100 抄 ASIN,榜单里混着手持风扇、桌面风扇,主图一眼能分辨,但 100 多个一个个扫过去也要花不少时间。
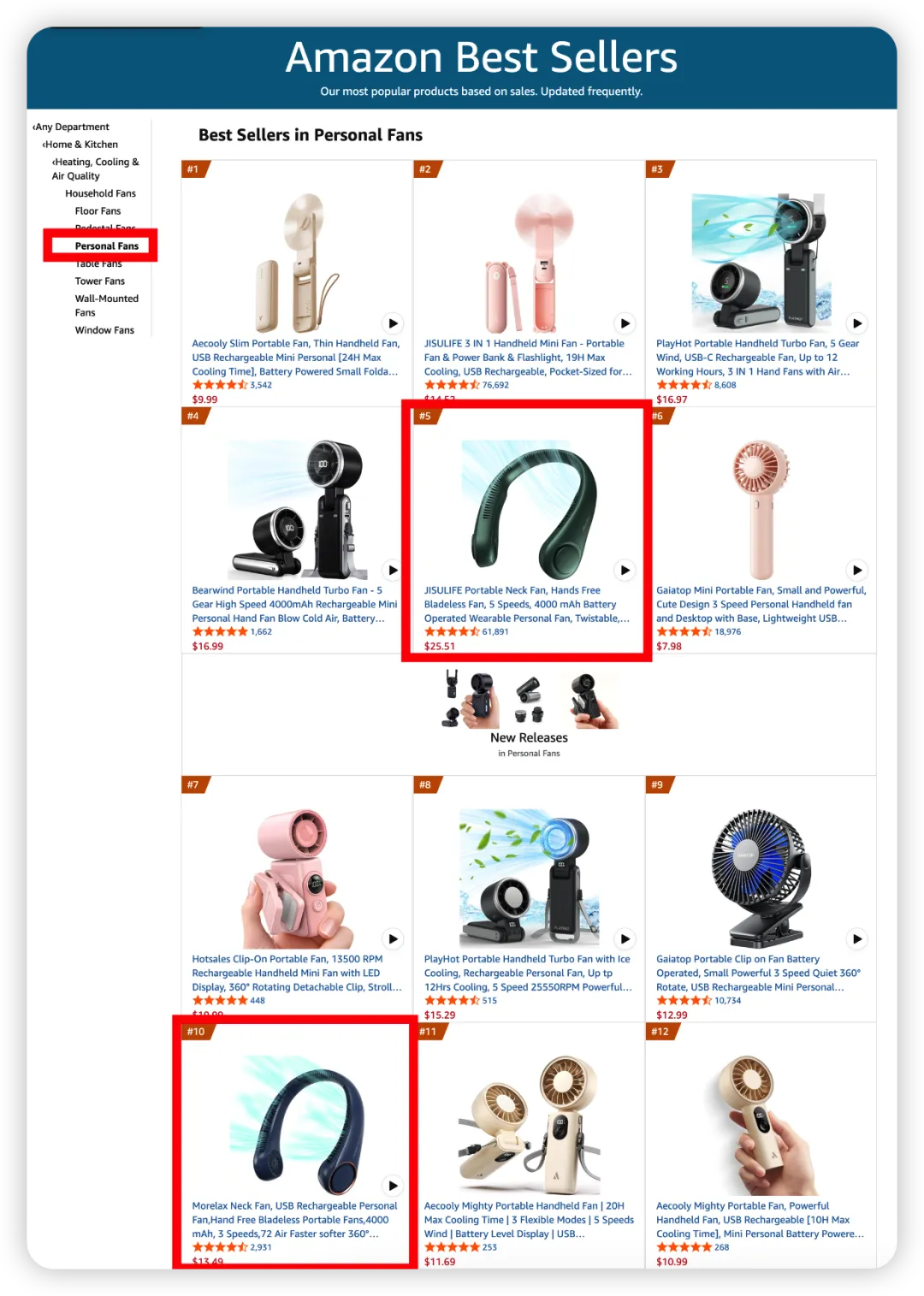
图源:亚马逊Best Sellers页面
前100 抄完还不够,我们还要去搜 "neck fan"、"portable fan"、"wearable fan" 等多个关键词搜索结果页继续扒 ASIN,找的过程极其麻烦——不确定有没有覆盖到所有大词,每个搜索结果页都要翻好几屏。
仅仅是 ASIN 收集这一步,就要 3-4 天。 然而即便花了这么多时间,我们心里依然没底——万一漏掉了几个卖得好的产品,ASIN 库就出现了盲区。
接下来还要逐个查每个 ASIN 的销量、关键词、品牌、评分等数据,再用 Excel 拼图算市场体量、竞争格局、关键词布局、评分门槛——这一整套做完,差不多要一周多。
最尴尬的是——假如 ASIN 库本身就有漏洞,算出来的 CR10、市场体量都会跟着偏,而我们压根不知道自己漏了什么。
新旧工作流对比

合计一周多 → ASIN 库可能有杂质、还可能漏 → 上层分析跟着偏 → 选品决策跑偏。
这个流程的根问题不是"我们不够努力",而是工具给的起点就错了。
BSR类目选品存在一定局限
这个局限主要体现在两个方面:
类目颗粒度不够细
亚马逊的 BSR 类目树更适合作为平台榜单参考,但在一些细分市场里,类目划分未必足够细。
比如我们想研究“挂脖风扇”这个细分方向,BSR 里可能并没有一个完全对应的独立类目,更多时候只能在 “Personal Fans” 这类更宽泛的类目中去查找。
这就会带来一个问题:不同使用场景、不同产品形态的商品,可能被放在同一个大类目下。我们在基于 BSR 榜单整理 ASIN 时,就需要额外判断:哪些是真正的同类产品,哪些只是被归到同一个大类目里。
商品归类可能存在偏差
大多数卖家会选择相对匹配的BSR类目,但因为分类不够细,只能把挂脖风扇填进"个人风扇",把桌面加湿器填进"手持风扇"。我们照着 BSR 榜单扒 ASIN,前 10 个里混进两个不相关的产品是常事。
更麻烦的是,BSR 榜单只能看到前 100 名。我们要组建完整的类目产品库,得从榜单、关键词搜索结果页到处扒数据,手动筛选、去重、归类。耗时耗力不说,产品库还不干净——错漏的数据上再做分析,结论自然不可靠。
BSR 类目存在局限 → ASIN 库可能不够准确 → 市场验证产生偏差 → 选品判断从一开始就可能跑偏。
西柚洞察怎么解决--准、细、多
我们建立了一套自研的 ASIN 分类算法,对亚马逊全市场的 ASIN 重新归类。逻辑不依赖卖家填的 BSR,而是基于产品属性、关键词关联、流量结构等多维数据,把真正属于同一个类目的 ASIN 归到一起。
这套算法把上面那一周多的工作流压缩成 10 分钟,并且让"准、细、多"这三件事第一次可以同时做到。
准--从根上解决“同类”问题
我们做了什么:分类算法不依赖卖家自填的 BSR,而是用产品属性、关键词关联、流量结构等多维数据交叉判断同类——结果是分类干净、不混入其他品类。
例子:如果我们想研究"挂脖风扇",亚马逊里根本没有这个类目,只能去看它在 "Personal Fans" 下的排名。在 BSR 搜 "Personal Fans",前 10 条里有 2 条是挂脖风扇,往下翻还有更不相关的东西混进来。
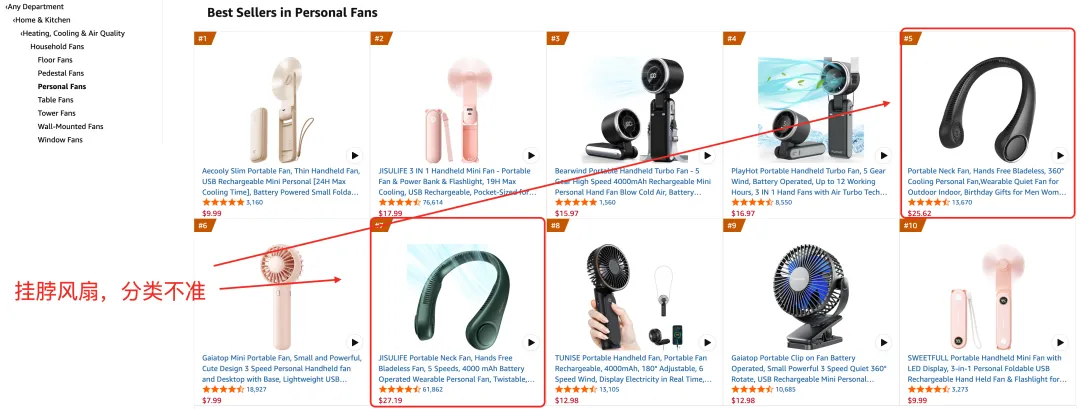
西柚分类后的"挂脖风扇"类目,一共1815个ASIN,634个活跃中,没有其他风扇混进来。这才是能拿来做市场分析的数据底子。

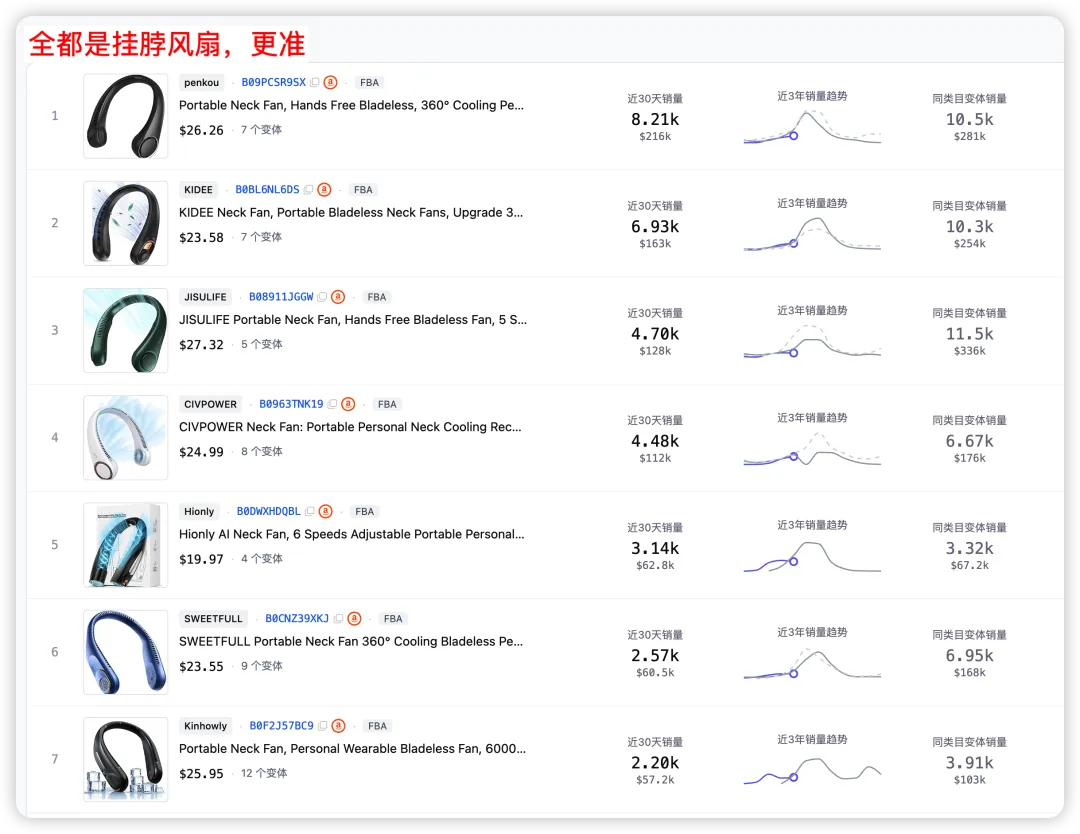
图源:市场洞察--市场榜单--销量榜
细--细到亚马逊原生类目难以覆盖层级
我们做了什么:亚马逊 BSR 按父体 ASIN 归类,一个父体下挂多个子体也只能进一个类目;我们按子体 ASIN分类,能把同一父体下、面向不同细分市场的子体拆开。
例子:iPhone 手机壳。亚马逊 BSR 只能给"Basic Cases"一个大类——手机壳就是手机壳,不分型号。
但现实中,一个父体 ASIN 下挂了 iPhone 14、iPhone 15、iPhone 16、iPhone 17 多个子体。这些子体面对的是完全不同的市场:
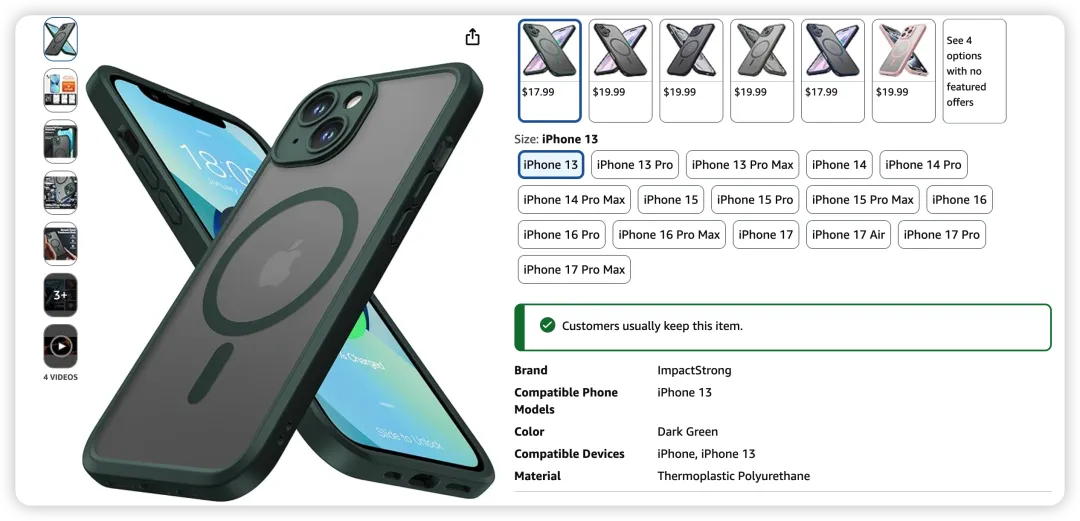
iPhone 16 用户和 iPhone 17 用户的购买窗口完全错开(17 刚发新机时正是 16 用户的换壳低谷)
不同型号的尺寸、摄像头开孔位置、磁吸结构都不一样,竞品也不重合
评分门槛、价格段、关键词也都不一样
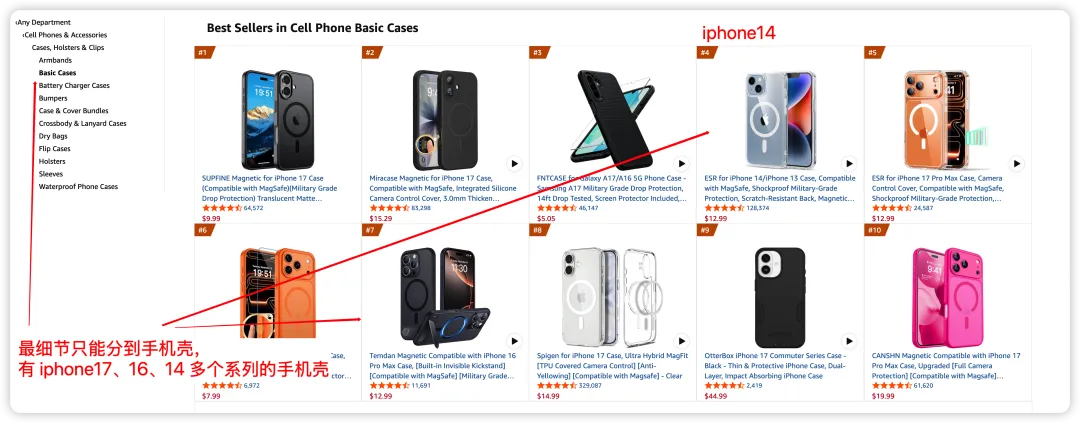
亚马逊把这些子体当成同一个 ASIN 在统计,但西柚把同一父体下的子体拆到 "iPhone 16 手机壳" / "iPhone 17 手机壳" / "iPhone 16 Pro Max 手机壳" 各自独立的类目里。
我们做选品时能精准看到每个型号各自的市场体量、竞品、评分门槛——这是平台原生类目/榜单维度难以直接呈现的。
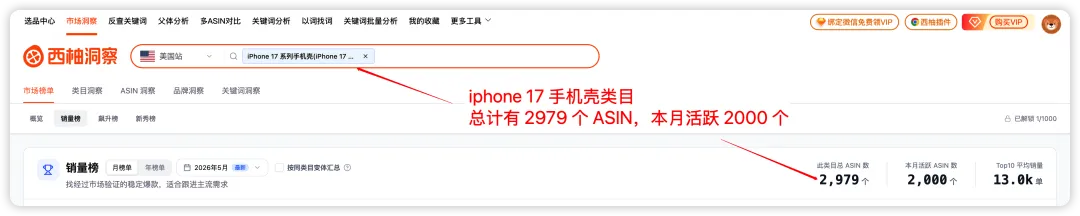
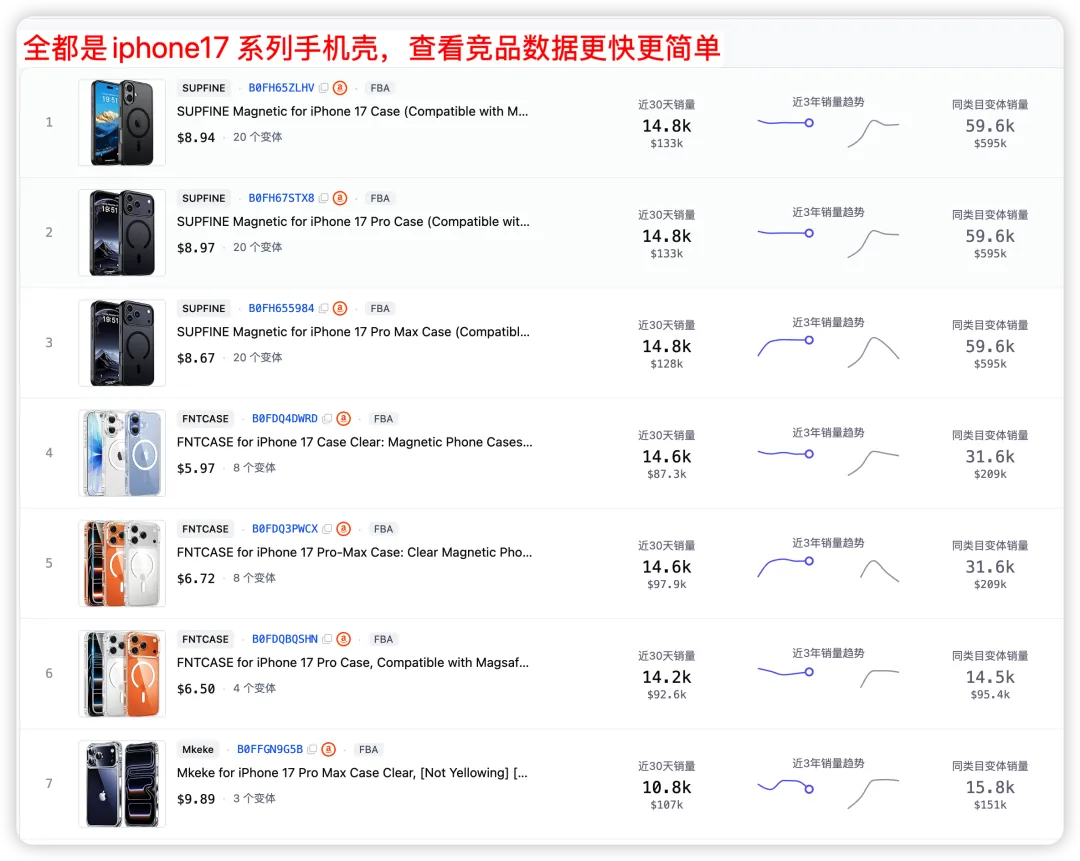
图源:市场洞察--市场榜单--销量榜
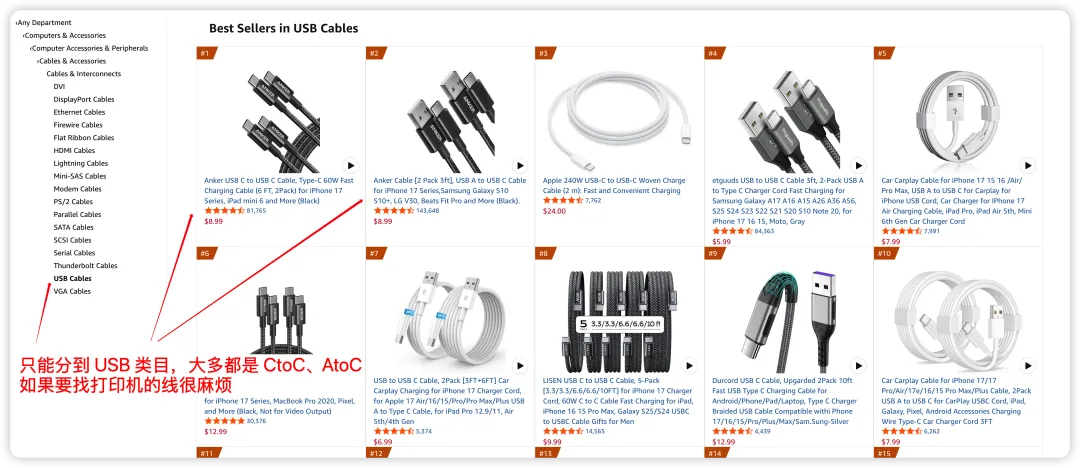
如果是打印机数据线,亚马逊只能分到 USB Cables,但是我们可以分到更细节的 A 转 B 数据线或者是 C 转 B 数据线。

多--覆盖全量ASIN+历史数据回溯
空间维度:一个类目就是完整的全量
我们做了什么:BSR 只能看实时前 100,西柚一个类目就是整个市场的全量 ASIN。
之前我们组建类目产品库需要跨多个 BSR 类目 + 多个关键词搜索结果页手动拼,耗时 3-4 天。但这种方式还会有问题:由于主要依赖当前榜单和搜索结果页,我们只能识别当前仍有排名或曝光的 ASIN。对于历史上销量表现较好但已下架、断货或排名消失的 ASIN,都可能出现遗漏,进而影响后续市场体量、竞争格局和增长趋势的判断准确性。
现在,一个西柚类目就能完整覆盖历史产品库。
以挂脖风扇为例,西柚共收录了 1815 个 ASIN,这些 ASIN 均满足“历史任意一个月销量大于 50”的标准,覆盖了历史上真正有过销售表现的产品。
而如果只依赖当前 BSR 类目和关键词搜索结果页去手动拼接,我们能找到的往往只是“当前还活跃”的 ASIN。比如挂脖风扇类目中,近一个月出现在任意 ABA 搜索词前 3 页的活跃 ASIN 只有 634 个。也就是说,即使把当前关键词搜索结果页尽可能搜全,仍然可能漏掉约 2/3 曾经销量大于 50 的历史 ASIN。
这些被遗漏的 ASIN,可能曾经是类目里的热销产品,只是现在已经下架、断货、排名消失,或不再出现在当前搜索结果中。如果产品库只基于当前可见 ASIN 搭建,就会低估类目的历史销量规模,同时高估类目的近期增长表现。
所以,西柚把“找 ASIN”这件原本需要 3–4 天手动拼图的体力活,变成了一键完成;更重要的是,它不仅能找到当前活跃产品,还能把历史上卖得好的 ASIN 一并纳入,避免因为样本遗漏造成市场判断偏差。

图源:市场洞察--类目洞察
时间维度:历史数据可回溯
我们做了什么:亚马逊 BSR 历史数据是黑盒——榜单只有实时排名,看不到任何月份的历史。西柚支持回溯 2024 年 1 月以来任意月份的榜单和数据。
很多类目跟季节强相关,淡季看数据会觉得"市场不大",但旺季一来销量可能翻好几倍。如果只拿淡季数据做判断,结论一定是错的。
例子:挂脖风扇。现在是 5 月,西柚可以切回去年 5-7 月,看真实旺季的竞争格局、价格段分布、品牌集中度,然后基于旺季数据做今年的备货决策。
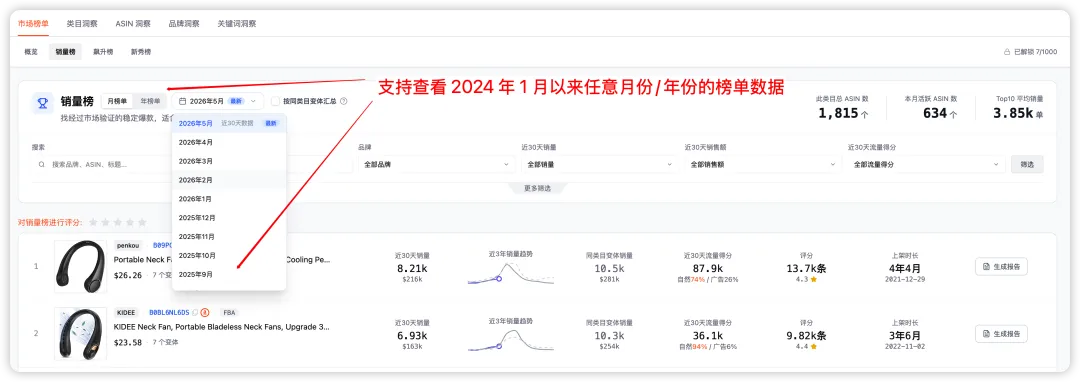
图源:市场洞察--销量榜--历史月份数据切换
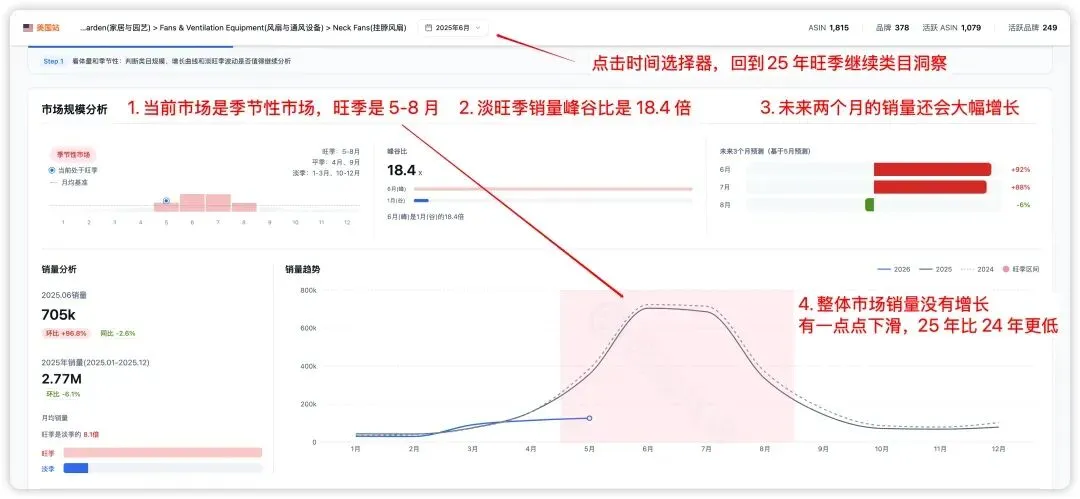
图源:市场洞察--类目洞察
其他典型的季节性类目(同样适合用历史回溯看真实旺季):
圣诞灯串 — 旺季 11-12 月

万圣节灯串 — 旺季 9-11 月

总结
回到开头那个问题——为什么我们的类目分析从一开始就错了?
因为工具给的起点就不对:BSR 是卖家自填的所以不准,按父体 ASIN 归类所以不细,只给实时前 100 所以不全、也没有历史。我们一开始扒到的 ASIN 库就有漏洞,后面所有分析都跟着错。
西柚做的事情就是把这个起点修正过来:
起点对了,后面所有分析才有意义。












