




Accio Work如何省Token,如何省积分,小技巧分享给你!

 882
882大家一直都比较关系,这个Accio Work后面如何省Token,如何省积分呢,今天给大家分享下小技巧:
## 积分 & Token 最佳性价比深度研究报告
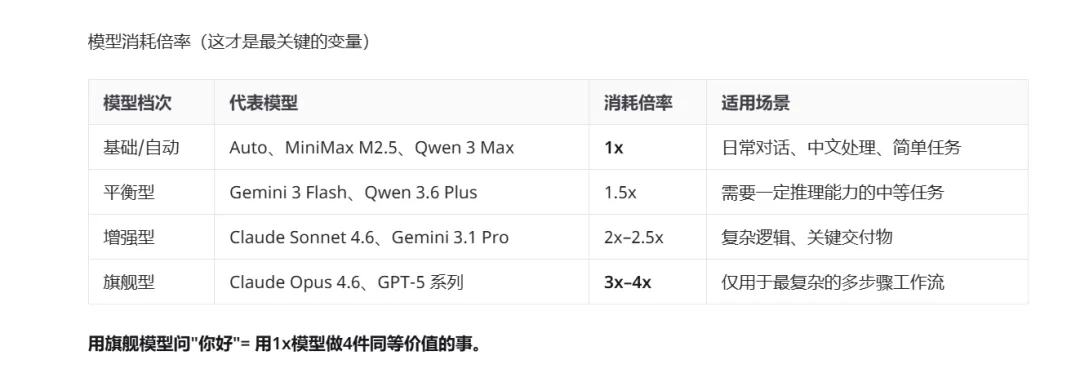
#### 模型消耗倍率(这才是最关键的变量)
### 二、Token 是怎么在你不知情时爆掉的
这是大多数人完全不知道的底层机制:
#### 1. System Prompt"底噪"
每次对话,AI 都要先读一遍它的指令手册(几千个 token),你还没发第一句话,积分就已经出去了。这是固定开销,无法避免,但可以通过**缓存机制**减少重复计费。
#### 2. 对话历史的"雪崩效应"(最大杀手)
AI 没有真正的记忆,每次回复前都要把**前面所有对话**重新输入一遍:
- 第1轮:输入 100 tokens
- 第5轮:输入 500 tokens(累加了前4轮)
- 第10轮:输入 1,000+ tokens(指数增长)
**你以为在问一个简单问题,实际上 AI 在消化你们的整段历史。**
#### 3. 工具调用的"隐性账单"
每次 AI 去搜索网页、读文件、执行代码:
- 网页 HTML 源码动辄数万 token
- 每步"思考-行动-观察"循环都在叠加上下文
- 5步完成的 Agent 任务,实际消耗是单次问答的 **8x–15x**
#### 4. 图片的"隐形杀器"
- 高分辨率图片会被切成多个 512×512 瓦片,每块都是独立 token 开销
- 分析一张截图的成本 = 分析 1,000 字文本的 **数倍**
---
### 三、10条可操作的性价比策略(按省量排序)
#### 策略1:任务完成即开新对话 — 省 50%–80%
**做法:** 每完成一个独立任务,就点"新建对话",彻底清空上下文。
**为什么:** 旧任务的对话历史会作为冗余数据随新任务一起输入,越聊越贵。
#### 策略2:分级用模型 — 省 70%–90%
**做法:**
- 闲聊、格式整理、简单翻译 → **Auto / Qwen(1x)**
- 重要文案、分析报告 → Claude Sonnet(2x)
- 极复杂工作流(如多步骤爬取+分析+写报告)→ 才用旗舰(3–4x)
**永远不要用旗舰模型做普通事。**
#### 策略3:文本优先于图片和视觉 — 省 60%–90%
**做法:** 能复制文字就不截图;能上传 TXT/Markdown 就不上传 PDF。如果要让 AI 分析某网站,直接给 URL 让它抓文本,不要截图。
#### 策略4:先压缩文档,再深挖 — 省 70%+
**做法:** 面对长文档,先问"提取本文档核心要点(3–5条)",然后基于摘要提问,不要直接把 100 页 PDF 投进去让它总结。
#### 策略5:一次下达批量任务 — 省 30%–50%
**做法:** 不要"帮我改A段"→等待→"再改B段"→等待→"再改C段"。
改成:"请同时修改以下三段内容,规则如下……"
每次回复都要重发 System Prompt 和上下文,少交互就少烧钱。
#### 策略6:给 Agent 明确边界,防止死循环 — 避免100%浪费
**做法:** 任务指令里加上"如果2次尝试失败,立即停止并告诉我"、"只搜索前3个结果"。
Agent 进入死循环时会疯狂空转,一分钟能把一天的配额烧光。
#### 策略7:直接给 URL,别让 AI 自己搜 — 省 数千 token/次
**做法:** 让 AI 查资料时,直接告诉它目标链接。别说"去查一下XX公司的产品",改成"访问这个页面:https://xxx.com/products"。
省掉"搜索-点击-跳转-加载"整条链路的 token 消耗。
#### 策略8:限制输出格式 — 省 10%–20%
**做法:** 明确说"仅输出 JSON"、"3句话内回答"、"不要客套语"。
输出 token 通常比输入更贵,砍掉废话直接省钱。
#### 策略9:利用模块化手动断点 — 省 40%
**做法:** 第一轮让 AI 给出方案/大纲,然后新开对话,把方案粘贴进去执行具体步骤。虽然多了一个手动步骤,但彻底切断了中间过程的上下文积累。
#### 策略10:善用 Auto 模式,让系统帮你省 — 系统级优化
**做法:** 不确定用什么模型时,选 **Auto**。系统会根据任务复杂度自动匹配最经济的模型,避免手动选高档模型造成的浪费。
---
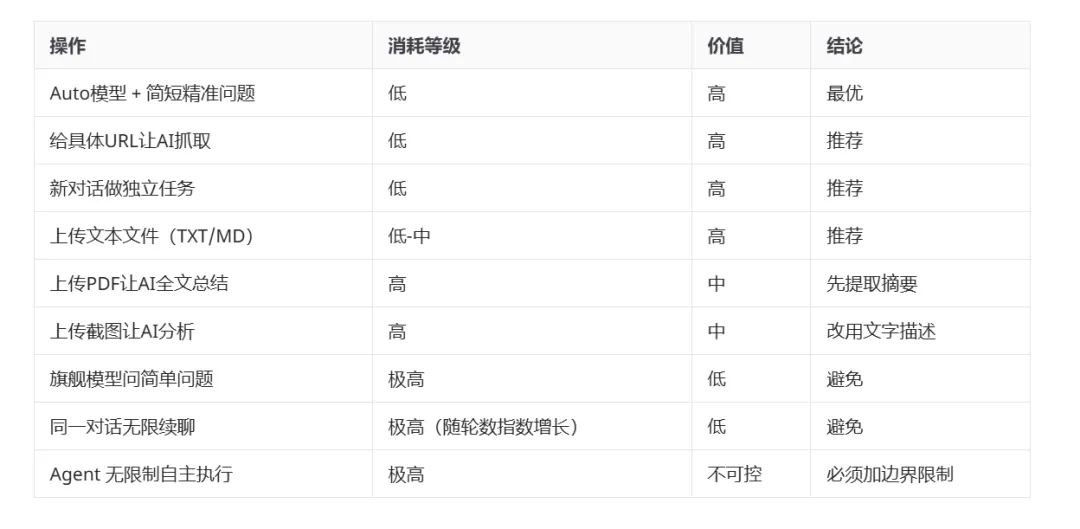
### 四、高消耗 vs 高价值 对照表
---
### 五、一句话总结
> **省积分的核心逻辑:勤开新窗口 + 分级用模型 + 任务描述越精准越省 + 绝不让AI看你们的聊天历史。**
你的每一条对话历史,都是下一次调用的成本。清空它,是最简单也最有效的省钱操作。












