



如何爬动态加载的页面?ajax爬虫你有必要掌握

 13851
13851通过前面几期Python爬虫的文章,不少童鞋已经可以随心所欲的爬取自己想要的数据,就算是一些页面很难分析,也可以用之前介绍的终极技能之「Selenium」+「Webdriver」解决相关问题,但无奈这种办法效率太慢,咋整?
今天就为大家介绍Ajax异步加载的数据的爬取。
↓↓↓
Ajax,全称为Asynchronous JavaScript and XML,即异步的JavaScript和XML。它不是一门编程语言,而是利用JavaScript在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。对于传统的网页,如果想更新其内容,那么必须要刷新整个页面,但有了Ajax,便可以在页面不被全部刷新的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行了数据交互,获取到数据之后,再利用JavaScript改变网页,这样网页内容就会更新了。

通俗来讲:就像一栋房子,先把框框架架搭起来(前端页面框架),再给他装修、置办家具(填充数据),这里的装修、置办家具即是ajax请求的数据。。
我们可以通过一些网站的事例来直观的了解一下什么到底是什么是ajax。
例如访问“蘑菇街”电商平台中的食品类目:http://list.mogujie.com/book/food/52026,通过Chrome浏览器可以看到我们与“蘑菇街”交互的所有数据。
示范:
打开Chrome,访问
http://list.mogujie.com/book/food/52026
在Chrome中按F12或者在页面空白处点击鼠标右键→检查。
点击Clear 和 XHR 按钮。
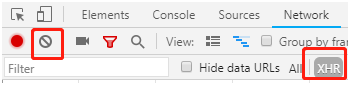
刷新一下页面。
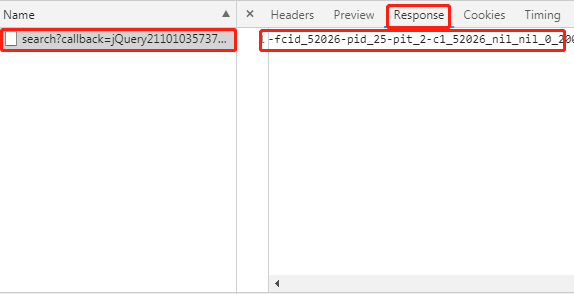
点击一下左边的search?callback=JQuery….,再点击右边栏的Response其下方会出现一些看不懂,但又好像有点儿规则的数据。管他的,先Ctrl+A全选拷贝出来看看。(如果你把商品列表页继续下滑,会出现更多的这种数据哦。)
使用Chrome插件「JSON-hanle」或者访问:https://www.json.cn/将刚才拷贝的数据粘贴进去,点击OK。
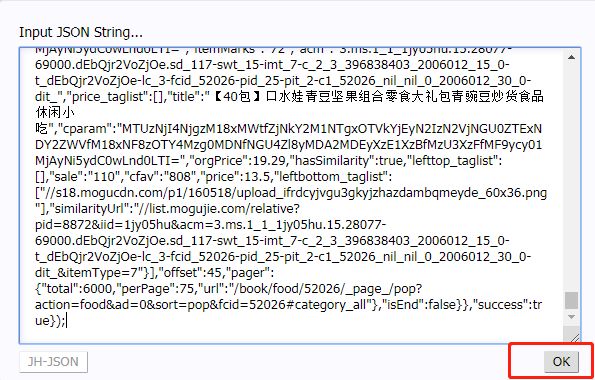
再与网页上的数据对比一下,见图:

怎么样?是不是一目了然,相关数据都在里面了。这里的orgPrice为原价、sale为销量、cfav为点赞、price为现价。这些数据都已经在这一串乱七八糟的字符里了,我们需要的就解析这串字符。
其实呢,这种数据格式叫做「Json」。json 是轻量级的文本数据交换格式,其格式与计算机语言中的字典(dict)类似,都是名称/值对(key/value)的格式。能拿到json数据就已经成功90%了,剩下的10%就是解析json拿出自己想要的数据、保存数据。但也不是所有的Ajax请求拿到的都是Json数据,例如亚马逊他就是这么66的。
下面将以我们日常能用到的,
爬取reviews来演练一遍Ajax请求:
访问某商品的所有reviews页面:https://www.amazon.com/product-reviews/ + ASIN
reviews能按照我们预想的方式排列,在操作下图中的筛选条件后会生成新的链接。

如将SORT BY切换为Most recent,浏览器地址栏的链接会变为:https://www.amazon.com/product-reviews/B072DXSF6S/ref=cm_cr_arp_d_viewopt_srt?pageNumber=1&sortBy=recent
若直接使用requests.get该链接,返回的数据并不会按照预想的顺序排列。这种时候就需要抓包、Ajax请求登场了。
Chrome中按F12或者在页面空白处点击鼠标右键→检查。
首先点击Clear按钮,清除已捕获到的数据。再点击Next→按钮,看一下加载一页新的reviews会捕获到哪些数据。如下图,捕获到了一个名为“cm_cr_arp_d_paging_btm_3”的文件。最后点击Response,看一下这句文件到底传输了些什么。
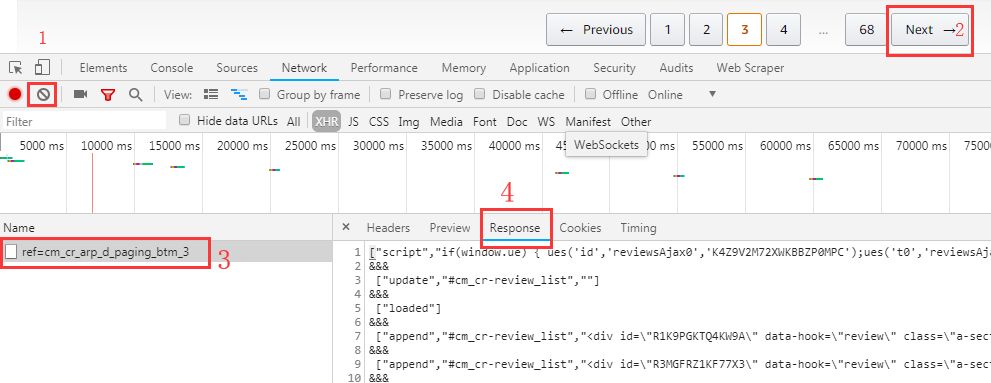
如下图所示,在Response里的数据与网页前端页面的部分源码一致。可以认定,亚马逊是先将评论页面的框架搭好,然后通过Ajax的方式传输显示评论详情的前端代码。

再分析一下本次数据传输的headers、data等数据。这一步非常重要,在数据交互中各类请求头、请求参数都会影响本次请求的返回值。

在上图中已将一些关键的参数做了解释,方便大家理解。
下面就是敲代码时间了,按照之前的逻辑我们可以直接使用Ajax请求数据,然后根据返回的数据获取到reviews的网页源码,再加以解析。
首先准备好headers、cookies等数据。前期后童鞋表示headers什么的太难搞了,且不知道这里面花里胡哨的一堆是啥意思,今天告诉大家一个简便方法。首先在Chrome控制台抓到的数据上点击鼠标左键→Copy→Copy as cURL。如图:

再访问https://curl.trillworks.com/,在“curl command”中将刚才拷贝的cURL粘贴进去,右边将自动生成Python代码。如图:
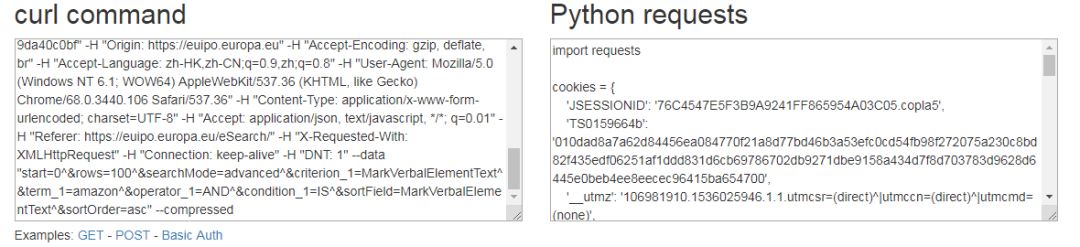
嘿嘿嘿,爽不爽。现在只需要把右边的“Python requests”拷贝出来,粘贴到Pycharm里就可以跑起来啦,是不是美滋滋?。
8、打开Pycharm,新建项目,将代码拷贝进去。可以看到我们需要的headers, cookies, data全都已经备好了。稍微加工一下,跑一下看看。
response = requests.post('https://www.amazon.com/hz/reviews-render/ajax/reviews/get/', headers=headers, data=data)
打印的为:
这与刚才在Chrome看到的一样,证明我们成功获取到了数据。
9、将数据整理一下,并删除不需要的垃圾数据。
html_list = list(response.text.replace('&&&', '').split(' '))
reviews_html_list = html_list[6:26]
print(len(reviews_html_list))
for i in reviews_html_list:
if len(i)==0:
reviews_html_list.remove(i)
10、遍历整个列表取出每个评论的ID。
for reviews_html in reviews_html_list:
frist_review_soup = BeautifulSoup(eval(reviews_html)[2], 'lxml')
review_id = frist_review_soup.find('div', 'a-section review')['id']
11、写一个解析review详情页的方法,方便调用。
def request_reviews_url(review_id):
headers = {
'origin': 'https://www.amazon.com',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-HK,zh-CN;q=0.9,zh;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'content-type': 'application/x-www-form-urlencoded;charset=UTF-8',
'accept': 'text/html,*/*',
'referer': 'https://www.amazon.com/product-reviews/B00CJHZRW8/ref=cm_cr_arp_d_viewopt_srt?ie=UTF8&reviewerType=all_reviews&sortBy=helpful&pageNumber=1',
'authority': 'www.amazon.com',
'x-requested-with': 'XMLHttpRequest',
'dnt': '1',
}
review_url = 'https://www.amazon.com/gp/customer-reviews/' + review_id
review_html = requests.get(review_url, headers=headers)
review_soup = BeautifulSoup(review_html.text, 'lxml')
review_title = review_soup.find('a', 'review-title').text
print(review_title)
review_author = review_soup.find('span', 'review-byline').text.replace('By', '')
print(review_author)
review_date = review_soup.find('span', 'review-date').text.replace('on ', '')
print(review_date)
review_text = review_soup.find('span', 'review-text').text
print(review_text)
这样就能完成让评论按要求排列,并爬取的需求了。附完整代码:
import requests
from bs4 import BeautifulSoup
def request_reviews_url(review_id):
headers = {
'origin': 'https://www.amazon.com',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-HK,zh-CN;q=0.9,zh;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'content-type': 'application/x-www-form-urlencoded;charset=UTF-8',
'accept': 'text/html,*/*',
'referer': 'https://www.amazon.com/product-reviews/B00CJHZRW8/ref=cm_cr_arp_d_viewopt_srt?ie=UTF8&reviewerType=all_reviews&sortBy=helpful&pageNumber=1',
'authority': 'www.amazon.com',
'x-requested-with': 'XMLHttpRequest',
'dnt': '1',
}
review_url = 'https://www.amazon.com/gp/customer-reviews/' + review_id
review_html = requests.get(review_url, headers=headers)
review_soup = BeautifulSoup(review_html.text, 'lxml')
review_title = review_soup.find('a', 'review-title').text
print(review_title)
review_author = review_soup.find('span', 'review-byline').text.replace('By', '')
print(review_author)
review_date = review_soup.find('span', 'review-date').text.replace('on ', '')
print(review_date)
review_text = review_soup.find('span', 'review-text').text
print(review_text)
if __name__ == '__main__':
page = 1
headers = {
'origin': 'https://www.amazon.com',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-HK,zh-CN;q=0.9,zh;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'content-type': 'application/x-www-form-urlencoded;charset=UTF-8',
'accept': 'text/html,*/*',
'referer': 'https://www.amazon.com/product-reviews/B00CJHZRW8/ref=cm_cr_arp_d_viewopt_srt?ie=UTF8&reviewerType=all_reviews&sortBy=helpful&pageNumber=1',
'authority': 'www.amazon.com',
'x-requested-with': 'XMLHttpRequest',
'dnt': '1',
}
while 1:
data = {
'sortBy': 'recent',
'reviewerType': 'all_reviews',
'formatType': '',
'mediaType': '',
'filterByStar': '',
'pageNumber': str(page),
'filterByKeyword': '',
'shouldAppend': 'undefined',
'deviceType': 'desktop',
# 'reftag': 'cm_cr_arp_d_viewopt_srt',
'pageSize': '10',
'asin': 'B072SS1NTM',
# 'scope': 'reviewsAjax1'
}
response = requests.post('https://www.amazon.com/hz/reviews-render/ajax/reviews/get/', headers=headers, data=data)
html_list = list(response.text.replace('&&&', '').split(' '))
reviews_html_list = html_list[6:26]
for i in reviews_html_list:
if len(i) == 0:
reviews_html_list.remove(i)
for reviews_html in reviews_html_list:
frist_review_soup = BeautifulSoup(eval(reviews_html)[2], 'lxml')
review_id = frist_review_soup.find('div', 'a-section review')['id']
request_reviews_url(review_id)
page += 1
爬虫中数据的分类主要有:结构化数据(json,xml等)和非结构化数据(HTML)。之前的文章中使用的案例都是从目标网站拿到非结构化数据然后使用正则表达式/xpath等解析,而今天讲是相对而言的结构化数据,可以使用json或xpath转换为Python对应的数据类型。寻找结构化数据可能在前期不好着手、找不到Post的正确URL,但一旦成功后将事半功倍。
照Web发展的趋势来看,以Ajax加载数据的方式将会越来越普遍。这种方式在Web开发上可以做到前后端分离,从而降低服务器直接渲染页面带来的压力。如果大家兴趣的话也可以自己动手尝试爬取一些其他网站的数据哟。
教了大家好几期的爬虫,大家有学会了的吗?觉得有用的小伙伴可以分享下朋友圈!或有什么问题,欢迎留言讨论哦!










