




AI 搜索靠两套「记忆系统」运转,但各平台的用法完全不同

 116
116★为什么同一个品牌,在一个 AI 引擎上是最新信息,在另一个上却是过时内容?如何判断每个平台到底在调用哪套记忆?
”
把关于你品牌的同一个问题,分别拿去问四个不同的 AI 搜索引擎,你大概率会得到四个不同的答案。一个答案是最新的,还引用了你刚发布的页面;另一个描述的是你 18 个月前就放弃的品牌定位,而且什么来源都没引用;第三个干脆通过竞争对手的对比文章来介绍你。同一个品牌、同一个问题、四种呈现方式——而且这些差异不是可以一笑置之的「模型抽风」,它们是结构性的。一旦你看清了这个结构,就可以针对它做规划。
我之前在《当训练数据截止日期成为排名因素》一文中提出过一个观点:
你的品牌如今同时活在两套不同的记忆系统里。
一套是参数记忆(parametric memory)——在模型训练时被「烤」进参数里的知识,训练完成后就被冻结,直到下一次训练才会更新。另
一套是检索(retrieval)——在用户提问的那一刻实时抓取的内容。那篇文章讲的是这种区分对「时机」意味着什么。
而这篇要讲的,是我当时刻意留到现在单独展开的部分:
各家引擎对这两套记忆的依赖方式并不相同,而正是这种差异,决定了你的品牌会出现在哪里、以及出现时呈现成什么样子。
每个引擎都有自己的「记忆姿态」
我先给这个东西起个名字,因为有了名字才好针对它做规划。一个大语言模型的记忆姿态(memory posture),就是它的默认倾向:
当你问它问题时,它是去做实时检索,还是直接用参数里已有的知识作答?
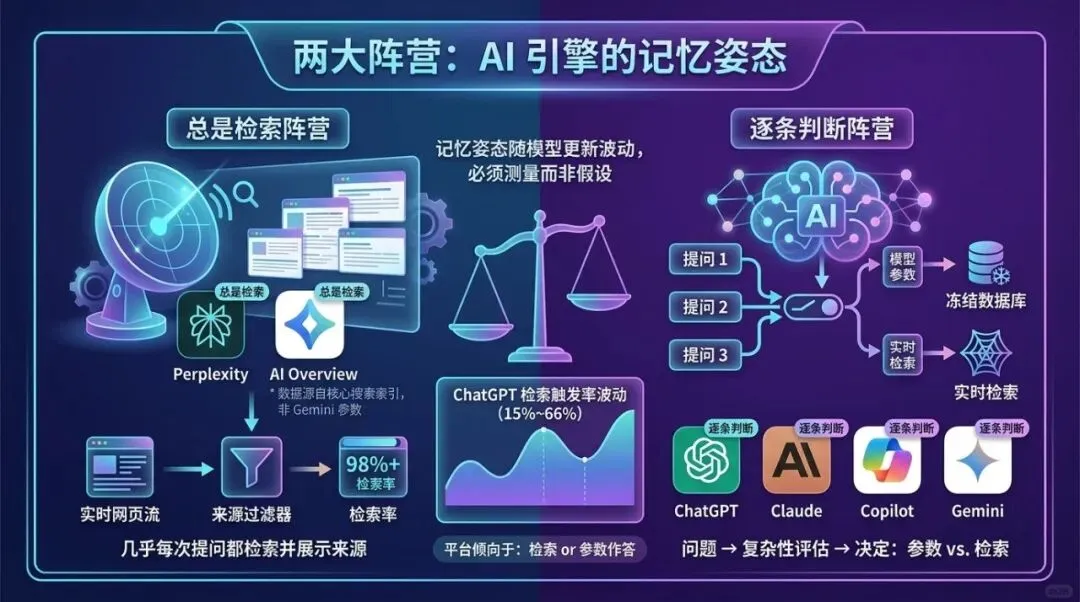
各平台大致分成两个阵营,而一个引擎属于哪个阵营,几乎决定了你的内容通过这个入口触达用户的全部方式。
一边是几乎每次提问都会检索的引擎。Perplexity 是最典型的例子:
它对基本上每一个问题都会执行实时网页搜索,并且把信息来源作为产品设计的一部分展示出来,而不是偶尔为之。
Google 的 AI Overviews 和 AI Mode 也偏重检索,但有个值得注意的细节:这些功能由驱动自然搜索结果的同一个爬虫提供服务,数据来自核心搜索索引,而不是 Gemini 的参数记忆。
Google 提供的用于控制模型训练的 Google-Extended 标记,对搜索结果及其 AI 功能中出现的内容没有任何影响。所以在这类「总是检索」的引擎上,你的可见性首先是一个检索问题,几乎不是参数问题。
另一边是逐条问题做判断的引擎。ChatGPT、Claude、微软 Copilot 和 Gemini 应用,都会对每个问题做一次决策:是用参数作答,还是去网上抓取。Claude 的网页搜索是一个工具,由模型在判断「这个问题需要搜索」时自行调用。
Copilot 只在功能开启且提问确实需要时才会联网核实——而当管理员把网页接地(web grounding)功能关掉时,它会完全退回到模型的内部训练知识。这个细节呼应了我在《别再把 AI 可见性当成一个问题》中说的:检索是团队需要治理的三个层面之一。从内部看这一层就是:
在「模型自行决定」的引擎上,检索是否发生,可能取决于某人管理后台里的一个开关,而不是你内容本身的属性。
而且,即便在同一个引擎内部,这个姿态也不稳定。一项针对 ChatGPT 的点击流研究发现,触发网页搜索的会话占比在研究期间在大约 15% 到 66% 之间剧烈波动,随着底层模型的更新而变化。
你三月份问的问题可能由记忆作答,到了四月同一个问题却触发了实时联网——而你这边什么都没改。记忆姿态是一个移动靶,这正是为什么你必须去测量它,而不是去假设它。
检索早已不是「一步到位」
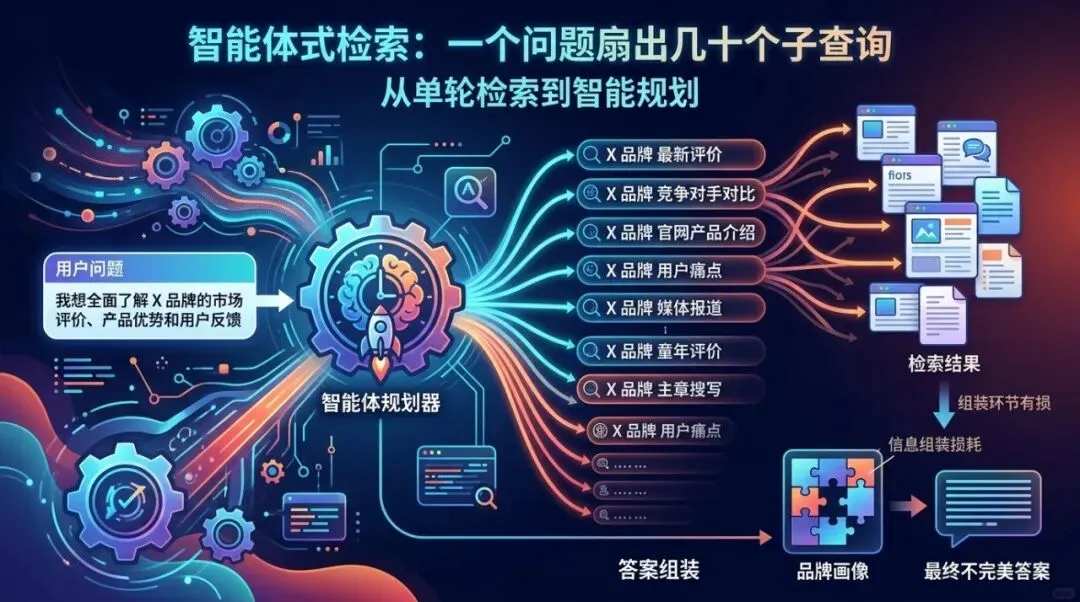
即便引擎确实执行了检索,「被检索到」也不再是一个干净利落的单一动作——很多老一套的优化直觉正是在这里悄悄失灵的。
过去的单轮模式是:系统把你的查询转成向量,抓取最匹配的几个页面,然后生成答案。如今它已经让位于智能体式检索(agentic retrieval):系统在作答之前会规划并执行大量子查询。用户输入的一个问题,会变成系统替用户发出的一连串问题,少则几个,多则几十个。你优化的对象不再只是搜索框里那个问题,而是引擎为了回答它而生成的那些「看不见的问题」。
在这之上还叠着一个二阶问题,值得明说,哪怕它将来值得单独写一篇。被拉进上下文,不等于被用好。最早记录模型如何不均匀地使用长上下文的研究,距今已近十年。
当前的模型基本解决了简单版本的问题——在长文档里找到一个被埋住的事实。但更难的事情依然不可靠:把分散在各处的多个信号整合成一幅连贯的图景。
你的品牌从来都不是一个单一事实。它的呈现质量,取决于引擎把你的页面、你的用户评价、以及散落在检索材料各处的第三方报道收集起来后,能否正确地组装。这个组装环节仍然是有损的——这意味着「我们被检索到了」和「我们被准确呈现了」是两件都可以测量、但可能互相矛盾的事。
「时机」成了一个过去不存在的杠杆
参数记忆引入了一个传统 SEO 时代根本不存在的变量:训练窗口。你无法编辑模型参数里已经存在的内容。
今天发布一篇更正声明,对一个去年夏天就完成训练的模型所编码的「你的品牌」毫无作用。唯一能改变参数记忆的是新一轮训练。
所以真正有用的问题不是「如何修正模型已经相信的东西」,而是「模型下次训练时会学到关于你的什么,以及你故事的正确版本,是不是它将会找到的那一个」。
这件事没有听起来那么绝望,原因有两个。
第一,参数记忆并不是一个你完全无法影响的黑箱。模型学到的是在大量来源中持续出现、相互印证的那个版本的事实。所以你要做的工作,就是让你故事的准确版本成为「冗余度最高」的版本——爬虫来抓取时想错过都难。
这是一场以模型代际而非页面修改为单位的长期游戏,但它是一场你可以参与的游戏。
第二,训练节奏已经不再是一年一次的慢动作。主流厂商如今频繁发布小版本更新,每个版本都带着自己的知识截止日期,所以参数层是以你可以实际瞄准的步频在刷新,而不是一个遥不可及的地平线。
团队反复报告的一些「不一致」现象——同一个引擎在不同日子给出不同答案——正是这个机制在起作用:某一天问题由参数作答,第二天触发了检索,而两个层面讲的不是同一个故事。
一套实操工作流:搞清楚你的品牌到底处在什么位置
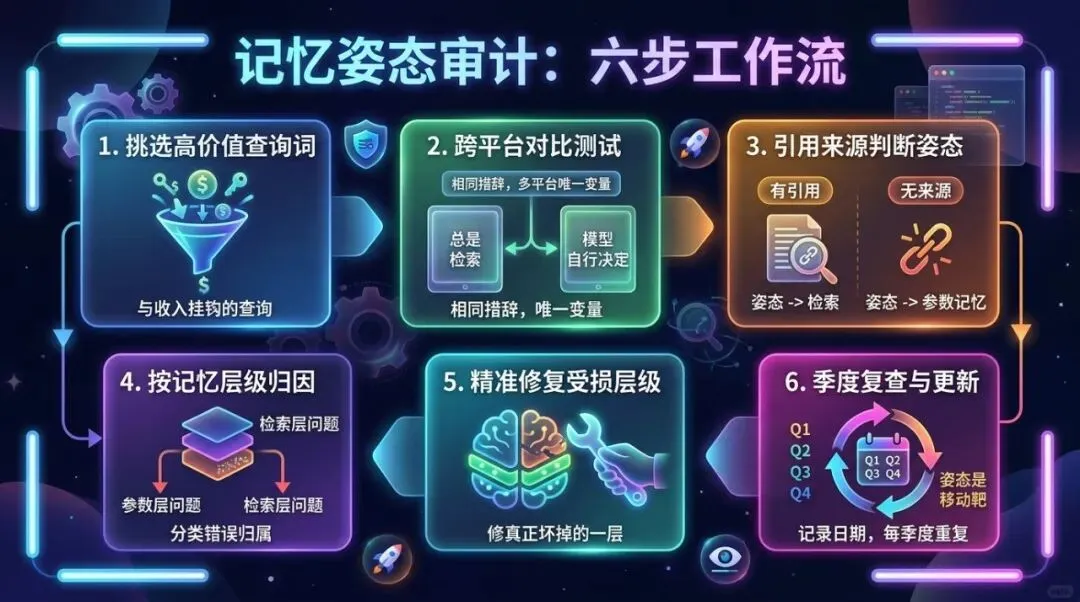
这套流程今天就可以手动执行,不需要任何特殊工具——这恰恰是重点。只要你理解了这两套记忆,你就能读懂任何引擎正在如何处理你的品牌。可以把它叫做「记忆姿态审计」。
1. 挑选真正值钱的查询词。不是单独的品牌名,而是买家实际会问、而你必须出现的那些问题:品类问题、对比问题、以痛点为出发点的问题。挑一小批,与收入直接挂钩的那种。
2. 在精心选择的多个平台上跑同一组问题。至少包含一个「总是检索」型引擎和至少两个「模型自行决定」型引擎,每次使用完全相同的措辞,让平台成为唯一变量。
3. 读的是姿态,不只是答案。引用来源就是破绽:有实时引用的来源,说明检索被触发了;一个自信满满却没有任何来源的回答,则来自参数记忆。在「模型自行决定」型引擎上,每个问题问两遍——一遍用平实的常规措辞,一遍加上「最新」「目前」这类时效性提示词,观察第二个版本是否会把引擎「掰」进检索模式。这个翻转,就是记忆姿态在暴露自己。
4. 按「哪套记忆产生了错误」来归类问题。没有引用的过时信息,指向参数问题;完全缺席,或者在一个明显执行了检索的引擎上通过竞争对手的页面被呈现,指向检索筛选问题。在输出结果里这两者看起来几乎一样,但它们不是同一种缺陷。
5. 修真正坏掉的那一层,因为修法不能互相套用:
6. 记录日期,定期重复。记忆姿态并不稳定,所以一次性的审计只是快照,不是结论。把它放进固定节奏里,至少每季度一次。
最后,一个值得认真想想的问题
大多数在做 AI 可见性优化的团队,都在拼命优化其中一套记忆系统,同时把另一套当成不存在——而且通常从来没有刻意决定过自己选的是哪一套。这件事要求的纪律说起来很简单,做起来很别扭:对每一个对你重要的引擎,搞清楚它的记忆姿态,搞清楚是哪套记忆在那里承载着你的品牌,并搞清楚——如果让你主动选,你会选这一层吗?
这就是「记忆层」之问,而大多数团队目前还回答不了——这本身就是诊断结果。
它也暴露了为什么「单一 AI 可见性评分」是一个范畴错误:一个把参数表现和检索表现压平成一个数字的指标,是在对两个独立变化、需要不同投入、以不同方式失效的东西求平均。
你压平了什么,就管理不了什么。现在真正重要的素养,是能在脑子里把这两层分开,并且每一次都问自己:我现在看到的,到底是哪一层?












