



如何使用 Python 和批量操作创建完美的亚马逊活动结构?

 10007
10007今天向大家展示如何利用编程语言 Python 和 Pandas 包来创建处理 Amazon 批量操作所需的电子表格。
什么是亚马逊广告批量操作?
什么是完美的广告系列结构?
如何使用 Python 创建新的批量工作表?
设置一些变量
外部工作表的附加信息
创建活动、广告组等的方法。
启动一切的主要方法
创建我们的亚马逊批量表
概括
一、什么是亚马逊广告批量操作?
亚马逊广告批量操作(我们称之为批量工作表)是 Excel 表格,其中包含完整活动结构,包括相关的绩效指标。我们可以创建新的广告系列或使用批量表格更新现有的广告系列。还可以在此处找到下载和上传批量工作表的页面:
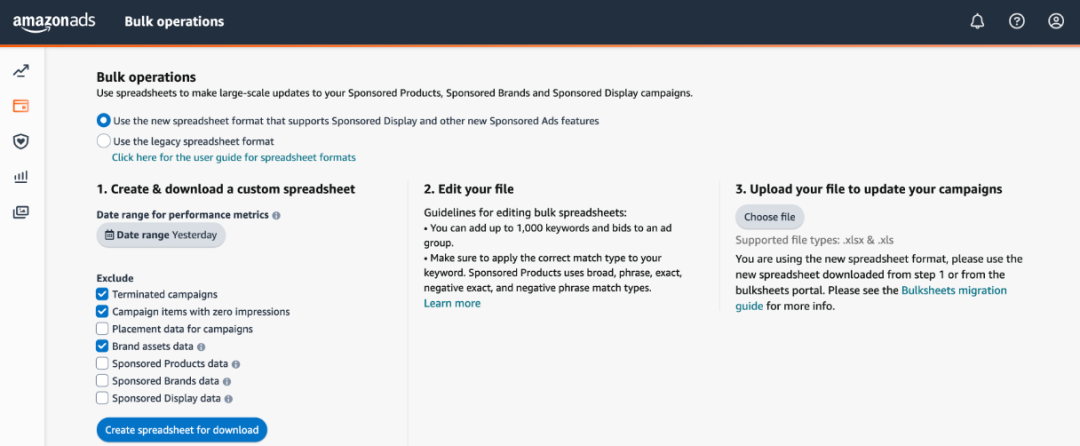
如果想批量创建或批量更新许多活动,而无需为每个活动逐一执行相同的操作,则批量工作表特别方便。
假设我们希望将 ACoS < 20 % 的 400 个商品推广活动中的每个活动的预算增加 10%。虽然我们可以在亚马逊的广告控制台中轻松做到这一点,但使用亚马逊的批量表格会更聪明。
它会像这样工作:
从广告控制台下载最新的批量表
例如 Microsoft Excel 中打开文件,然后转到“赞助产品”工作表
过滤我们感兴趣的活动的工作表
更改预算列,例如,使用临时列
保存文件并将其重新上传到亚马逊
但是,今天我们不想着眼于更新现有的广告系列,而是为产品创建新的广告系列。
二、什么是完美的广告系列结构?
我们通常为单个产品或产品系列创建非常具体的活动。例如我们通常会创建以下手动商品推广活动:
1 个具有通用关键字目标的广告系列(通用意味着关键字不包含任何品牌名称)
1 个带有攻击性关键字目标的广告系列(攻击性意味着我们针对竞争对手的品牌)
1 个具有攻击性产品目标的广告系列(即针对竞争对手的产品)
1 个具有防御性关键字目标的广告系列(防御性意味着我们针对包含我们的品牌或产品名称的关键字)
1 个具有防御性产品目标的广告系列(即针对我们的产品)
这样做是因为进攻性、通用性和防御性广告系列通常会显示非常不同的绩效指标,例如,竞标我们的品牌比竞标竞争对手的品牌“便宜”得多。通用运动通常比“进攻性”运动“昂贵”少,但另一方面,比“防御性”运动更昂贵。这意味着我们需要为每种类型设置不同的性能目标。如果 ACoS 是我们的主要目标,那么与防御活动相比,进攻活动需要更高的 ACoS 目标。
如果我们将所有目标都放在一个广告系列中,那么我们的情况就会好坏参半。当然,我们可以在目标级别管理此广告系列,但我们将如何分配预算?例如,将如何允许我们的防御性活动的预算高于我们的进攻性活动?这是不可能的。这是我们拆分广告系列的另一个原因。但是,为单个产品/产品系列创建这五个活动需要一些工作。这就是我们使用 Python 实现自动化的地方。
三、如何使用 Python 创建新的批量工作表?
要从头开始创建为给定产品创建有意义的活动的批量表,我们首先需要一些信息:
应该宣传哪些 ASIN 或 SKU?
自己和竞争对手的品牌是什么?
要定位的关键字是什么?
要定位的产品是什么?
我们需要组织这些信息,例如,在不同的 Excel-Sheet 或 Google Docs 中。我们将这些信息组织在单独的文本文件中。我们有其他脚本或多或少地自动创建这些文本文件,例如,从现有的(但无组织的)活动中创建。
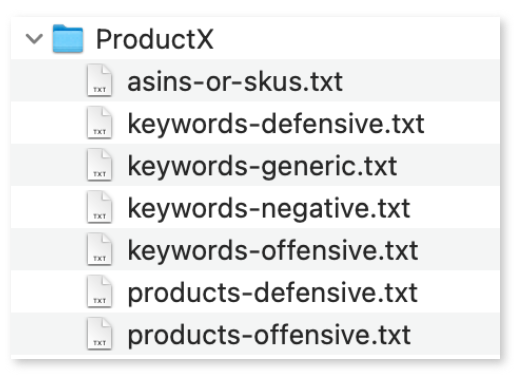
(产品和关键字数据存储在不同的文本文件中)
我们为每个 ASIN、SKU 或 ASIN/SKU 组创建这些文件。然后脚本将遍历每个文件夹并为每个产品(组)创建这五个活动。因此唯一需要做的就是填充这些文件、运行脚本、上传批量工作表,然后就可以开始了。
以下是脚本的主要组成部分。显示每个代码行会占用太多位置,因此我们将专注于最重要的事情。
四、设置一些变量
由于我们将创建一个新的批量工作表,因此我们需要了解批量工作表及其不同实体的结构。与广告组或关键字目标相比,我们必须为广告系列定义不同的值。
例如,要创建一个新的广告系列,我们需要填写以下字段(如果我们下载,就会找到这些字段,例如,填充的批量表):
emptySpBulksheet ={ "Product":"Sponsored Products", "Entity":"", "Operation":"Create", "Campaign Id":"", "Ad Group Id":"", "Portfolio Id":"", "Ad Id (Read only)":"", "Keyword Id (Read only)":"", "Product Targeting Id (Read only)":"", "Campaign Name":"", "Ad Group Name":"", "Start Date":"", "End Date":"", "Targeting Type":"", "State":"", "Daily Budget":"", "SKU":"", "ASIN":"", "Ad Group Default Bid":"", "Bid":"", "Keyword Text":"", "Match Type":"", "Bidding Strategy":"", "Placement":"", "Percentage":"", "Product Targeting Expression":""}
这些是需要填写的列。一些列属于特殊实体,例如,每日预算列仅指活动实体,对于品牌推广和展示推广活动,然后我们定义一些变量来定义脚本的行为。这里有些例子:
# CampaigncreateSPCampaigns =TruecampaignStatus ="Enabled"# Enter “Enabled”, “Paused”, or “Archived”campaignDailyBudget =20# EUR or USDcampaignBiddingStrategy ='Dynamic bids - down only'# Enter "Dynamic bids - down only", "Dynamic bids - up and down", or "Fixed bid".campaignStartDate = time.strftime("%Y%m%d")# Today as default, e.g. "20220529"campaignEndDate =""# “yyyymmdd”, can be empty# Adgroup (https://advertising.amazon.com/API/docs/en-us/bulk sheets/sp/sp-entities/sp-entity-ad-group)adgroupMaxBix =1.50 adgroupStatus ="Enabled"# Enter “Enabled”, “Paused”, or “Archived”# KeywordkeywordDefaultMatchType ='broad'negativeKeywordDefaultMatchType ='negativeExact'# negativePhrase or negativeExact# Toggles: Here you can define which type of targets to create (true) or not (false)addKeywordsGeneric =TrueaddKeywordsDefensive =TrueaddKeywordsOffensive =FalseaddProductsOffensive =FalseaddProductsDefensive =False
我们对其他广告类型(SB、SD)执行相同的操作。
五、外部工作表的附加信息
有时我们还使用带有一些附加信息的 Excel 表格。与文本文件相比,使用 Excel 有时更容易。假设有一个单独的工作表,其中文件名存储在mainInputFile带有两张工作表的变量中:
品牌和产品名称
竞争对手的品牌和产品名称
要将这些品牌添加到我们的 python 脚本中,我们将执行以下操作:
# Read additional data from main input file (Google Doc -> Excel Sheet)xls = pd.ExcelFile(mainInputFile)dfB = pd.read_excel(xls, engine="openpyxl", sheet_name="Our brands")dfC = pd.read_excel(xls, engine="openpyxl", sheet_name="Competitor brands")ownBrands = dfB['Brand'].unique().tolist()competitorBrands = dfC['Brand'].unique().tolist()# Make sure brands are lowercaseownBrands =list(map(str.lower, ownBrands))competitorBrands =list(map(str.lower, competitorBrands))
我们还做一些数据并将所有内容转换为小写,这使得以后的比较更容易。也可以将其硬编码到脚本中,但这种方法使其更加灵活,如果像我们那样与多个客户端一起工作,就很方便。
六、创建活动、广告组等的方法。
在下一步中需要定义一些函数/辅助方法,以便构建批量工作表。以下是创建结构化广告系列名称的示例,该名称也反映了广告系列的目标:
defgetCampaignName(targeting ="Manual", campaignType ="SP", type1="keyword", type2 ="generic", groupName ="default"): prefix ="RE-"+ campaignType +"-" # targeting if targeting =="Manual": targetingPrefix ="MANU-" else: targetingPrefix ="AUTO-" # type1 if type1 =="keyword": type1Prefix ="KW-" else: type1Prefix ="PT-" # type 2 if type2 =="generic": type2Prefix ="GEN-" elif type2 =="offensive": type2Prefix ="OFF-" else: type2Prefix ="DEF-" groupName = groupName.strip() groupName = groupName[:30].upper() campaignName = prefix + targetingPrefix + type1Prefix + type2Prefix + groupName +'-'+ randomString return campaignName
如上所见,我们的广告系列名称以前缀开头,因此可以轻松识别我们的广告系列。然后添加以下字符串:
“MANU”或“AUTO”,如果它是手动或自动活动(仅适用于商品推广活动)
“KW”或“PT”,如果它是关于关键字或产品定位的
使用“GEN”、“OFF”或“DEF”表示目标类型(通用、进攻或防御)
产品名称(组)
每次运行脚本时都会更改的随机字符串
随机字符串使得过滤在单次运行中创建的活动变得容易,例如。如果犯了错误,我们可以轻松找到这些活动,例如,将它们存档并重新开始。然后我们创建不同的方法来创建实体,例如,这里有一个方法来填充创建活动所需的相关字段:
defcreateSpCampaign(targeting ="Manual", type1="none", type2 ="none", groupName ="none", customerPath ="none", counter =1, fileName =""): global bulkSheetSp campaignName = getCampaignName(targeting = targeting, campaignType ="SP", type1=type1, type2 = type2, groupName = groupName) campaign = copy.deepcopy(emptySpBulksheet)# Create a deep copy campaign['Entity'] ='Campaign' campaign['Campaign Id'] = campaignName campaign['Campaign Name'] = campaignName campaign['Start Date'] = campaignStartDate campaign['End Date'] = campaignEndDate campaign['Targeting Type'] = targeting.upper() campaign['State'] = campaignStatus campaign['Daily Budget'] = campaignDailyBudget campaign['Bidding Strategy']= campaignBiddingStrategy if((bulkSheetSp['Entity']=='Campaign')&(bulkSheetSp['Campaign Id']== campaignName)).any(): pass# Do nothing, we already have this campaign else: bulkSheetSp = bulkSheetSp.append(campaign, ignore_index=True) # Create adgroup createSpAdgroup(targeting = targeting, type1=type1, type2 = type2, groupName = groupName, campaignName = campaignName, customerPath = customerPath, counter = counter, fileName = fileName)
首先复制我们的“空批量表”并用所有必要的数据填充它。然后,此方法调用 next 方法createSpAdgroup,该方法执行与上图类似的操作,仅针对广告组。这将传递给广告系列的所有信息也会传递给广告组。
此方法如下所示:
defcreateSpAdgroup(targeting ="Manual", type1="none", type2 ="none", groupName ="none", campaignName ='none', customerPath ="none", counter =1, fileName =""): counterString =f"{counter:02}" global bulkSheetSp adgroupName = getCampaignName(targeting = targeting, campaignType ="SP", type1=type1, type2 = type2, groupName = groupName)+'-AG'+'-'+ counterString adgroup = copy.deepcopy(emptySpBulksheet)# Create a deep copy to not alter emptySpBulksheet adgroup['Entity'] ='Ad Group' adgroup['Campaign Id'] = campaignName adgroup['Ad Group Name']= adgroupName adgroup['Ad Group Id'] = adgroupName adgroup['State'] = adgroupStatus adgroup['Ad Group Default Bid']= adgroupMaxBix bulkSheetSp = bulkSheetSp.append(adgroup, ignore_index=True) # Create ad createSpAd(targeting = targeting, type1=type1, type2=type2, groupName=groupName, campaignName=campaignName, adgroupName=adgroupName, customerPath = customerPath) if type1 =="keyword": createSpKeywordTarget(targeting = targeting, type1=type1, type2=type2, groupName=groupName, campaignName=campaignName, adgroupName=adgroupName, customerPath = customerPath, fileName = fileName) if type1 =="product": createSpProductTarget(targeting = targeting, type1=type1, type2=type2, groupName=groupName, campaignName=campaignName, adgroupName=adgroupName, customerPath = customerPath)
我们以相同的方式定义了创建广告、关键字目标、产品目标、否定关键字等所需的所有其他方法。
七、启动一切的主要方法
然后需要我们的主脚本来启动它。比如这样:
if createSPCampaigns: # Create empty bulksheet bulkSheetSp = pd.DataFrame(data=emptySpBulksheet, index=[0]) # Get all products or product groups stored in different folders productGroups = list_paths(customerPath) productGroupsLength =len(productGroups) j =0 randomString = randStr(N=5)# Create a random string for productGroup in productGroups: j = j +1 # Check which files are available all_files =sorted(glob.glob(customerPath +'/'+ productGroup +'/*.txt')) counter =0 forfilein all_files: if(addKeywordsOffensive)&('keywords-offensive.txt'infile): createSpCampaign(targeting ="Manual", type1="keyword", type2 ="offensive", groupName = productGroup, customerPath = customerPath, fileName =file) if(addKeywordsGeneric ==True)&('keywords-generic.txt'infile): counter = counter +1 createSpCampaign(targeting ="Manual", type1="keyword", type2 ="generic", groupName = productGroup, customerPath = customerPath, counter = counter, fileName =file) if(addKeywordsDefensive)&('keywords-defensive.txt'infile): createSpCampaign(targeting ="Manual", type1="keyword", type2 ="defensive", groupName = productGroup, customerPath = customerPath, fileName =file) if(addProductsDefensive)&('products-defensive.txt'infile): createSpCampaign(targeting ="Manual", type1="product", type2 ="defensive", groupName = productGroup, customerPath = customerPath, fileName =file) if(addProductsOffensive)&('products-offensive.txt'infile): createSpCampaign(targeting ="Manual", type1="product", type2 ="offensive", groupName = productGroup, customerPath = customerPath, fileName =file)
出于教学原因,我删除了一些行,例如,在解析文件之前清理文件(删除空白行、删除重复的关键字等)。如果文件包含超过 1.000 个关键字,我们的脚本也会处理这种情况。如果使用排列,就会很快见效,因为我们想在广泛匹配的情况下使用词组匹配。
八、创建亚马逊批量表
最后但并非最不重要的一点是,我们需要将数据导出到 Excel 表,然后我们可以上传到亚马逊。
这像这样工作:
# Remove empty rowsif createSPCampaigns: bulkSheetSp['Entity'].replace('', np.nan, inplace=True) bulkSheetSp.dropna(subset=['Entity'], inplace=True)# Filenametoday = time.strftime("%Y-%m-%d-%H-%M")# Today as defaultoutputFile = customerPath +'/'+ today +'-'+ slugify(customer)+'-campaign-create-bulksheet.xlsx'outputFile = outputFile.replace("input-","")# Export to Excelwith pd.ExcelWriter(outputFile)as writer: if createSPCampaigns: bulkSheetSp.to_excel(writer, sheet_name='Sponsored Products Campaigns', index=False)
九、概括
一切就绪后,我们可以发挥创造力来快速填充这些 txt 文件或主输入表。以下是一些帮助大家入门的想法:
根据品牌分析中的搜索词报告快速生成关键字和产品目标创意
在这里也使用我们的亚马逊 SEO 研究中的关键字
如果我们的客户要求重新组织现有的活动并利用表现良好的关键字,例如,我们会解析现有的批量表并提取所有产品,包括。表现良好的目标。然后将每个目标放入正确的存储桶中,并在几分钟内运行脚本。
(免责声明:我们尊重原创。本平台提供的学习资料来源互联网和其它公众平台,主要目的在于分享信息,让更多人获得跨境行业学习资料,版权归原作者所有,内容仅供读者参考,如有侵犯您的权益或版权请及时告知我们,我们将尽快删除!)










