



为什么广泛匹配总跑出不相关的词,被80%卖家误判的相关性

 1902
1902

AI设计/3D打印/欧洲市场实战拆解,点击报名
如题,是前几天收到的一个卖家的问题
基于cosmo算法
我重新梳理了一下出现这种情况的原因逻辑
同时结合自己的操作习惯,说说如何应对
这个问题不能单纯的纠结于“相关性”的问题
因为广泛匹配跑出大量不相关词这个本来就是自身匹配逻辑(四种)决定的
而应该跳出相关性单一的判定标准看
多看一个维度---转化
这样才能弥补我们卖家和平台匹配算法间的认知差距
亚马逊定义的相关和我们认为的相关,本身是不对等的
所以我上面用引号的相关性
亚马逊定义的相关是有转化概率的相关
而我们卖家通常理解的是产品属性相关
在cosmo算法下,广泛匹配比之前字面匹配更广泛
这种情况在这两年的广告数据中体现的很明显
包括我自己看到的广告数据也是,这已经不是偶然个例
而是亚马逊广告底层匹配逻辑转变结果
我用一个公式来总结现在的广泛匹配
广泛匹配 = 字面相关 + 语义相关 + 行为数据相关
底层逻辑具体是怎么匹配的
1. 从词法匹配 -> 语义意图与行为相关匹配
AI时代下,我们不能继续把广泛理解为词干提取 + 同义词扩展的匹配
同时要考虑语义与意图匹配
字面相关词
这个是我们平常理解的产品属性相关词
如同义词、拼写错误、缩略词等
包括target词序变化、近义词扩展
语义相关词
除了简单的关键词扩展,也可能是意图相近词匹配(区别于字面相似)
语义的向量模型会通过判断搜索这个词的人,可能还会买什么
而不仅仅是target词包含哪些词干
行为数据相关词
基于用户真实购买行为,判断展示逻辑,而不是纯搜索数据
这些相关的行为包括共购数据、搜索路径、浏览-购买路径、用户画像聚类等
像搜A买B,那A和B可能会被算法关联
或者买A的人也买B,算法也会认为A和B相关
这些行为相关往往就导致我们卖家认为不相关
2. 什么决定广泛匹配的边界
这一点对于投放target很重要
投放的时候必须知道广泛匹配不会脱离Listing独立运行
Listing质量决定匹配边界
标题、五点描述、ST、A+页面、后台关键词、图片这些内容
决定了listing被系统怎样收录,也决定了listing在系统中的质量
如果listing出现关键词堆砌、跨类目词、多义词等,就会无形中扩大匹配半径
Listing内容越宽泛 -> 匹配就越发散
Listing内容越垂直 -> 匹配就越收敛
3. 历史数据会影响匹配边界
一个是历史的转化数据会影响系统判断相关性
历史数据中出现转化的词会让相关的词权重放大
包括一些偶然转化词,特别是数据本来就少的词,系统判断你的预估转化要比其他产品的高,曝光的概率就越高
另一个是新品或者数据少的,因为算法没有学习
系统也会主动扩大测试范围(在边界内),导致部分不相关词的出现
如何控制好广泛匹配的边界
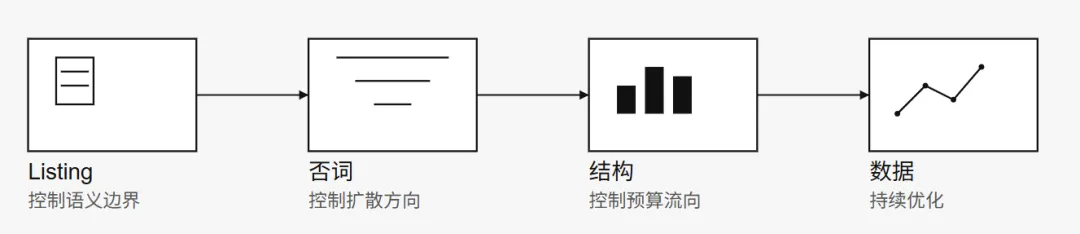
listing的质量这个就不用多说了,最基本的操作
起码要删除不必要的无关词,减少系统理解listing,减少歧义同时提高语义匹配一致性
这里主要从广告的维度展开
1. 养成前置否定的习惯
在做关键词调研的词库的时候,同时建立全局否定词库
在开广告时提取否定
2. 流量分层
不断把高转化词从广泛漏出
让exact起到提升关键词权重的作用,最后在广泛否词
让广泛和精准功能分离出来
或者通过词组匹配限制词序的同时保留关键词扩展能力
同时做好预算和竞价的比例控制,通过合理的预算结构去控制流量的分层效果
3. 用精准target作为锚点
遇到边界太泛的时候,可以新建一个获活动,将相关词的词根和词频统计出来
将频率的词根组合成后再去投放(这一步要检测词的搜索相关和流量)
4. 对广泛匹配的重新定位
不要局限的判断相关性和只看ACOS,可以通过拓词率(有效新词产出)和转化词贡献+TACOS结合判断
看看是否能够不断的带来能在exact盈利的转化词(让广泛弥补我们自认为的相关和算法认为的相关之间的差距)
最后是周期性的分析Search Term Report,不断的做相关性 + 转化双维度筛选





如题,是前几天收到的一个卖家的问题
基于cosmo算法
我重新梳理了一下出现这种情况的原因逻辑
同时结合自己的操作习惯,说说如何应对
这个问题不能单纯的纠结于“相关性”的问题
因为广泛匹配跑出大量不相关词这个本来就是自身匹配逻辑(四种)决定的
而应该跳出相关性单一的判定标准看
多看一个维度---转化
这样才能弥补我们卖家和平台匹配算法间的认知差距
亚马逊定义的相关和我们认为的相关,本身是不对等的
所以我上面用引号的相关性
亚马逊定义的相关是有转化概率的相关
而我们卖家通常理解的是产品属性相关
在cosmo算法下,广泛匹配比之前字面匹配更广泛
这种情况在这两年的广告数据中体现的很明显
包括我自己看到的广告数据也是,这已经不是偶然个例
而是亚马逊广告底层匹配逻辑转变结果
我用一个公式来总结现在的广泛匹配
广泛匹配 = 字面相关 + 语义相关 + 行为数据相关
底层逻辑具体是怎么匹配的
1. 从词法匹配 -> 语义意图与行为相关匹配
AI时代下,我们不能继续把广泛理解为词干提取 + 同义词扩展的匹配
同时要考虑语义与意图匹配
字面相关词
这个是我们平常理解的产品属性相关词
如同义词、拼写错误、缩略词等
包括target词序变化、近义词扩展
语义相关词
除了简单的关键词扩展,也可能是意图相近词匹配(区别于字面相似)
语义的向量模型会通过判断搜索这个词的人,可能还会买什么
而不仅仅是target词包含哪些词干
行为数据相关词
基于用户真实购买行为,判断展示逻辑,而不是纯搜索数据
这些相关的行为包括共购数据、搜索路径、浏览-购买路径、用户画像聚类等
像搜A买B,那A和B可能会被算法关联
或者买A的人也买B,算法也会认为A和B相关
这些行为相关往往就导致我们卖家认为不相关
2. 什么决定广泛匹配的边界
这一点对于投放target很重要
投放的时候必须知道广泛匹配不会脱离Listing独立运行
Listing质量决定匹配边界
标题、五点描述、ST、A+页面、后台关键词、图片这些内容
决定了listing被系统怎样收录,也决定了listing在系统中的质量
如果listing出现关键词堆砌、跨类目词、多义词等,就会无形中扩大匹配半径
Listing内容越宽泛 -> 匹配就越发散
Listing内容越垂直 -> 匹配就越收敛
3. 历史数据会影响匹配边界
一个是历史的转化数据会影响系统判断相关性
历史数据中出现转化的词会让相关的词权重放大
包括一些偶然转化词,特别是数据本来就少的词,系统判断你的预估转化要比其他产品的高,曝光的概率就越高
另一个是新品或者数据少的,因为算法没有学习
系统也会主动扩大测试范围(在边界内),导致部分不相关词的出现
如何控制好广泛匹配的边界
listing的质量这个就不用多说了,最基本的操作
起码要删除不必要的无关词,减少系统理解listing,减少歧义同时提高语义匹配一致性
这里主要从广告的维度展开
1. 养成前置否定的习惯
在做关键词调研的词库的时候,同时建立全局否定词库
在开广告时提取否定
2. 流量分层
不断把高转化词从广泛漏出
让exact起到提升关键词权重的作用,最后在广泛否词
让广泛和精准功能分离出来
或者通过词组匹配限制词序的同时保留关键词扩展能力
同时做好预算和竞价的比例控制,通过合理的预算结构去控制流量的分层效果
3. 用精准target作为锚点
遇到边界太泛的时候,可以新建一个获活动,将相关词的词根和词频统计出来
将频率的词根组合成后再去投放(这一步要检测词的搜索相关和流量)
4. 对广泛匹配的重新定位
不要局限的判断相关性和只看ACOS,可以通过拓词率(有效新词产出)和转化词贡献+TACOS结合判断
看看是否能够不断的带来能在exact盈利的转化词(让广泛弥补我们自认为的相关和算法认为的相关之间的差距)
最后是周期性的分析Search Term Report,不断的做相关性 + 转化双维度筛选


 热门活动
热门活动 
 其他
其他 04-09 周四
04-09 周四
 热门报告
热门报告 










