



企业数据模型在业务应用上的实践

 2238
2238数智化建模
现在大家频繁提及的“数智化”一词最早是2015年北京大学“知本财团”课题组提出的对“数字智商”(Digital Intelligence Quotient)的阐释,最初的定义是:数字智慧化与智慧数字化的合成。它有三层含义:一是“数字智慧化”,相当于云计算的“算法”,即在大数据中加入人的智慧,使数据增值增进,提高大数据的效用;二是“智慧数字化”,即运用数字技术,把人的智慧管理起来,相当于从“人工”到“智能”的提升,把人从繁杂的劳动中解脱出来;三是把这两个过程结合起来,构成人机的深度对话,使机器继承人的某些逻辑,实现深度学习,甚至能启智于人,即以智慧为纽带,人在机器中,机器在人中,形成人机一体的新生态。


数据采集完成后, 才是大数据工作的重头戏——数智化数据分析的开始。数智化的数据分析工作需要用到模型的方法来做预测或者分类,建模分析的基本流程是:
了解各个特征的业务含义和计算逻辑; 各个特征的分布是否符合预期? 特征之间的相关性如何,是否符合基本逻辑? 特征和目标值的相关性如何,是否符合基本逻辑?
根据特征的众数、中位数或者平均值来填充;
也可以对样本做分类,根据所在类的平均值众数等填充;
通过回归法来做样本填充,缺失值作为因变量,其他特征做自变量去预测;
还可通过比较复杂的方法,如多重插补法。

单变量数据异常识别方法包括:简单统计量分析、三倍标准差、箱线图;多变量数据异常识别是指,不只从一个特征去判读数据异常,而是在多个特征下来判断其是否异常。多变量异常数据识别的方法很多,比如聚类模型、孤立森林模型、one-class svm模型等。
对于很多模型,如线性回归、逻辑回归、Kmeans聚类等,需要计算不同特征的系数,或者计算样本距离。
这种情况下,如果不同特征的数值量级差别很大,会严重影响系数和距离的计算,甚至这种计算都会失去意义;所以在建模前必须要做的就是要去量纲,做标准化处理。当然有些模型是不需要做数据标准化处理的,如决策树、随机森林、朴素贝叶斯等。
1)最小—最大规范化
2)z值规范化
完成以上这四点工作后, 才能正式结合业务场景开始数据建模。

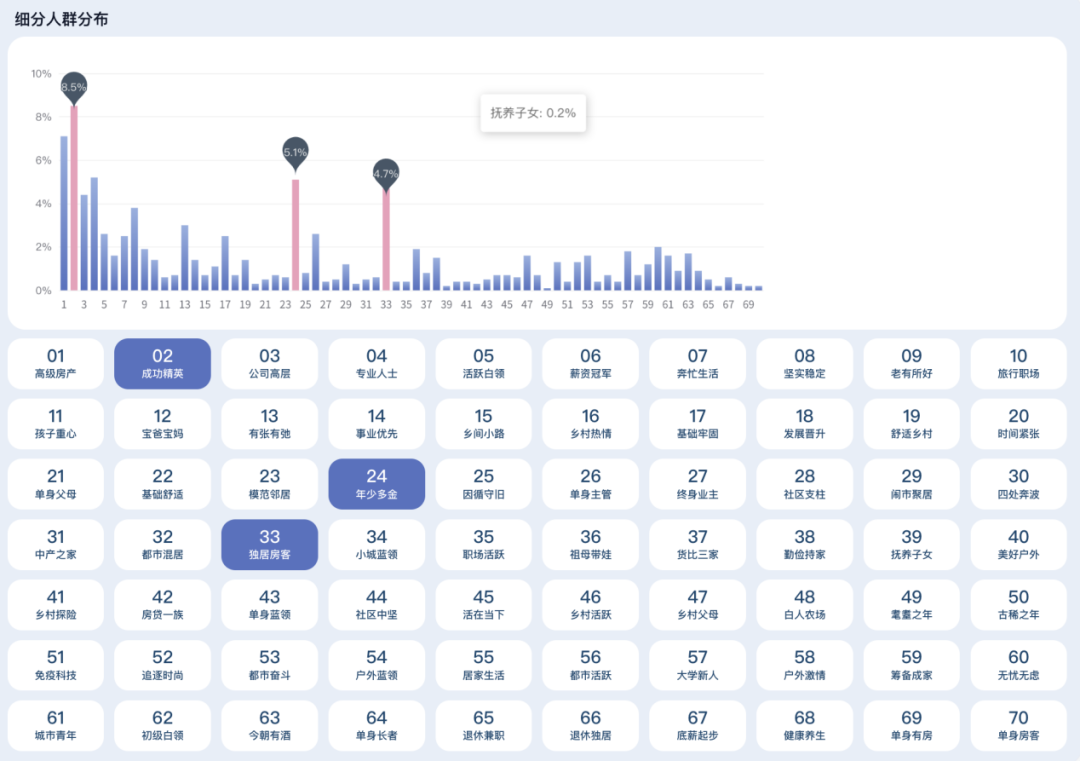
业务场景-人群细分:
在产品极其丰富的今天,很难找出一种产品适用于所有人。即便是品牌能够吸引大多数人,如可口可乐,也不得不推出“零糖”可乐以满足一部分消费者的需求。因此,营销人员要清楚目标客户有哪些。通常情况下,品牌会应用客户细分来为特定的目标客户提供服务,有效利用渠道、推广等资源来吸引潜在客户。
传统的细分策略,通常以年龄、性别、住址、职业等为依据。然而,互联网时代让社群成为消费者沟通的主要渠道,消费者惊奇地发现,潜藏在他们内心的偏好、特质居然在各个社群中得到了呼应,因而这些偏好、特质被激发了出来。他们主动给自己贴上标签,如一个上班时间不苟言笑的CEO可能是“萌宠”的爱好者,穿Prada的“女王”却是个“猫奴”。消费者身上的标签数量剧增,这进一步促成了对消费者的细分。
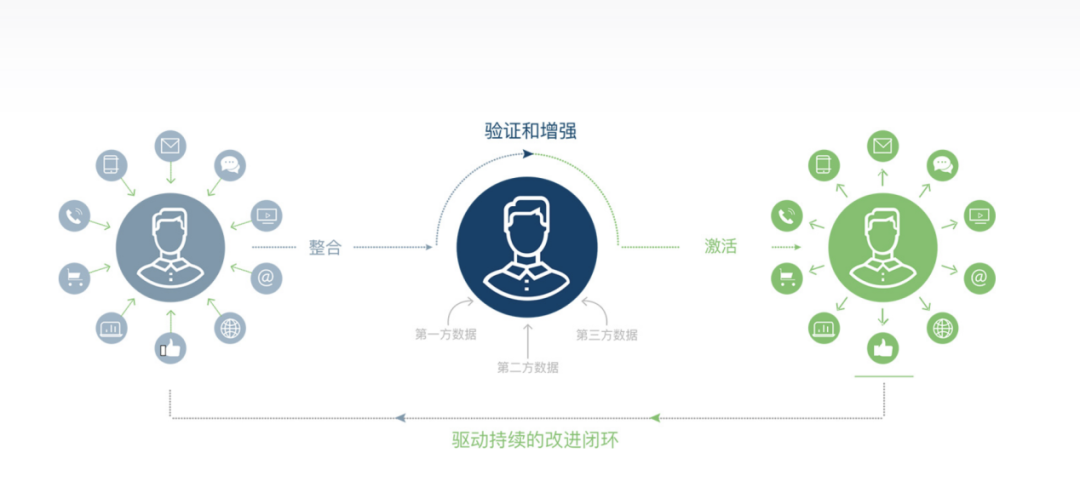
毫无疑问,市场细分和消费者角色建设都依赖于各种各样的数据,包括第一方调查数据、定性焦点小组数据、购买数据、行为数据、在线跟踪数据等。随着Martech和大数据的出现,通过整合、分析各种来源不同的数据,企业能够获得的不是对消费者的简单解读,而是详尽的市场细分和消费者角色建设。
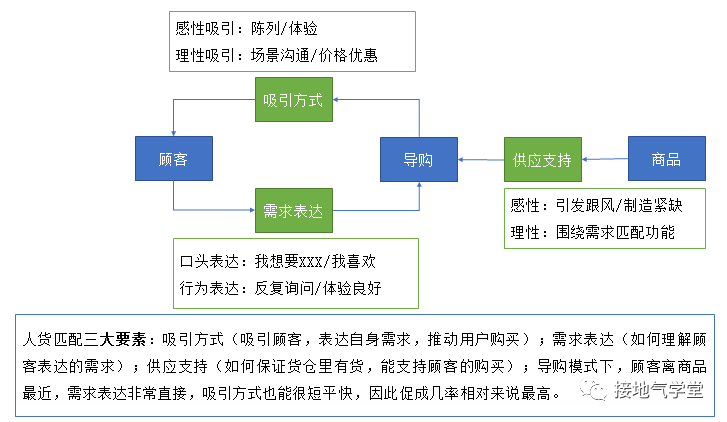
匹配模型就是要实现让系统作为导购(像向导一样引导购买),而不是推销员。不是无脑地推送信息和商品, 而是能够『察言观色』洞察用户的需求, 并且给他推荐最适合的商品。当然,不同商品,提升匹配成功率的手段也不同。比如, 场景式匹配,体验式匹配,陈列式匹配和价格式匹配等,综合这些要素,可以推导出导购型匹配的分析模型(如下):
今天分享的内容是博鼎国际数据模型在业务场景上的流程和体现,模型训练前的数据分析、数据清洗以及特征选择非常重要,甚至他们是决定建模是否成功的关键因素,也就是数智化的底层逻辑。欢迎关注我们的公众号,了解更多行业和技术的信息。










