



亚马逊运营必备爬虫知识:使用「Selenium」+「Chromedriver」爬僵尸链接

 41000
41000往期有读者朋友提问能否爬「僵尸链接」,肯定是可以的。只有你看不到,没有爬虫爬不了的。
使用本文今天将讲到的「Selenium」+「Chromedriver」就可以轻松完成。本文还是会从环境搭建、查找僵尸链接原理到代码编写一步步来实现这个需求。
Selenium原本是一套完整的web应用程序测试系统,现也用作爬虫。用户可以使用它驱动浏览器,使浏览器按照已编写完成的代码完成相应动作。
Selenium支持驱动Chrome、Firefox、IE等一系列浏览器,在这里我还是选用大家熟悉的Chrome浏览器。
一、安装Selenium:
在上一期已搭建Python环境的前提下打开CMD窗口,输入: 「pip install selenium」会自动安装selenium,如无报错,且提示安装成功,则成功安装selenium。
可以通过以下方式验证是否安装成功并且能正常使用:
在CMD窗口中输入python,再输入from selenium import webdriver,敲击回车。如果没有报错,则selenium成功安装且能正常使用。

二、下载Chromedriver:
首先从https://www.google.cn/chrome/下载最新版Chrome浏览器,再从http://chromedriver.storage.googleapis.com/index.htm 下载最新版的Chromedriver。
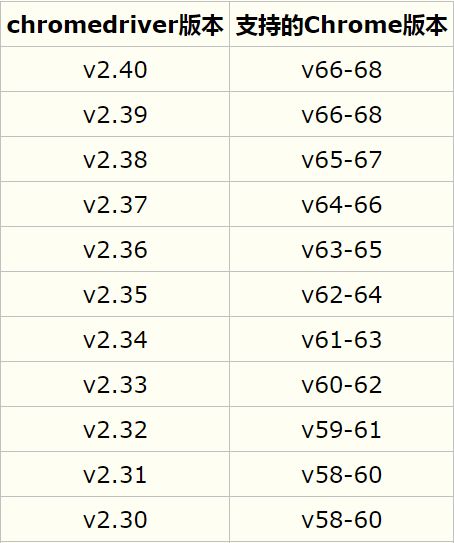
若你已经安装了Chrome浏览器,可根据已安装的Chrome浏览器版本下载对应的Chromedriver版本。附Chrome与Chromedriver的对应关系表:
在Chrome浏览器和Chromedriver都下载完成后,将Chrome浏览器安装好,将Chromedriver解压放在自己喜欢的地方待用。
在搜索引擎中使用「site」关键字,可以把搜索范围限定在特定站点中,如site:某某.com。“site:”后面跟的站点域名,不要带“http://”;site:后面带不带www结果可能是不一样的,因为有些域名还包括二级域名,如:site:www.某某.com和site:某某.com,搜索结果就不一样;另外,site:和站点名之间,不要带空格。
我们可以用「site:amazon.com」,只查找在亚马逊网站内的信息。
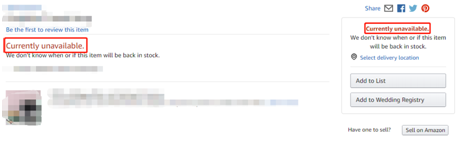
而一个僵尸链接必有下图特征:
那我们需要构建一个完整的搜索关键字使用Google就可以帮我们找出亚马逊中的僵尸链接。如我需要找「Nike」的僵尸链接,则使用「site:amazon.com Nike Currently unavailable.」使用Google搜索即可。
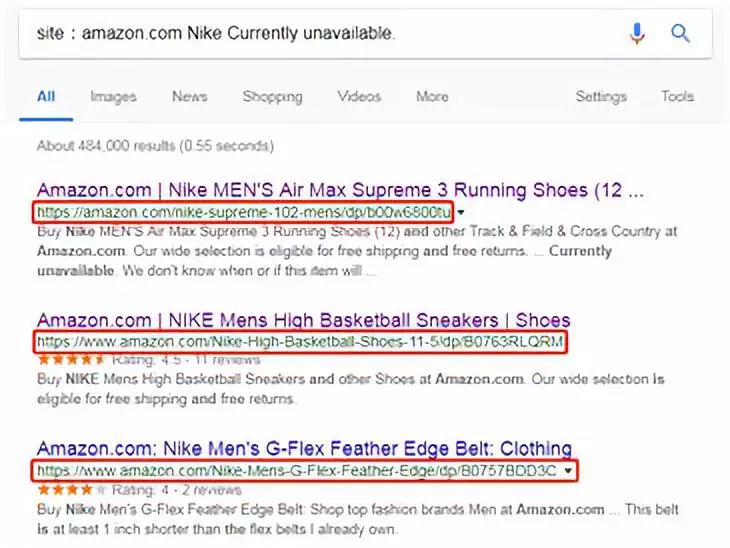
但其中某些搜索结果,并不是我们想要的僵尸链接。这就需要我们的爬虫去遍历每个搜索结果,并返回正确的僵尸链接。
打开Pycharm,新建项目:
从selenium导入webdriver:
from selenium import webdriver
准备好搜索链接:
url = 'https://www.google.com/search?q=site%EF%BC%9Aamazon.com+Nike+Currently+unavailable.'
driver = webdriver.Chrome('C:Program Files (x86)GoogleChromeApplicationchromedriver.exe')
# 在webdriver.Chrome(中填入之前下载好的Chromedrive的路径)
driver.get(url)
将自动打开Chrome浏览器并访问:https://www.google.com/search?q=site%EF%BC%9Aamazon.com+Nike+Currently+unavailable.
若浏览器出现「Chrome 正受到自动测试软件的控制。」则表示我们已成功使用selenium驱动Chrome并按照预设访问了Google。

分析Google搜索结果页面,在搜索结果页面按F12。通过分析网页源码,可以看出每个搜索结果都包含在一个class为rc的<div>标签内:
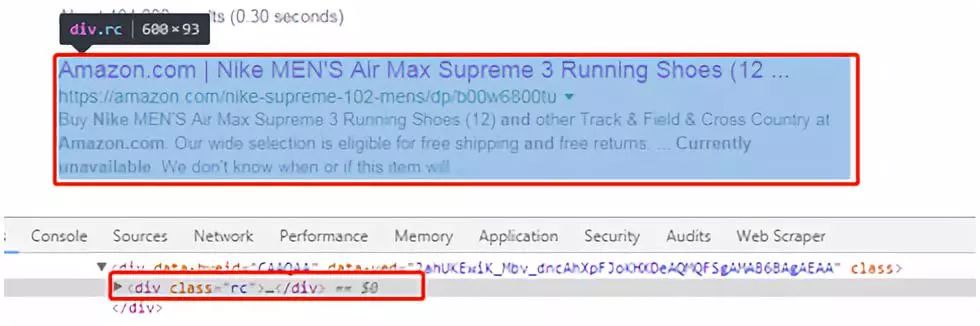
我们可以使用「XPath」来查看是否通过查找所有的class为rc的<div>标签即可找到所有搜索结果。首先下载Chrome插件「XPath Helper」:
在搜索结果页面打开「XPath Helper」,输入「//div[@class='rc']」,显示「RESULTS (20)」及表示有20个class为rc的<div>标签,这与页面中的20个搜索结果相符,这表示可以使用该XPath找出页面中共有多少个搜索结果。

再按照下图分别点击1、2定位某条搜索结果的标题:
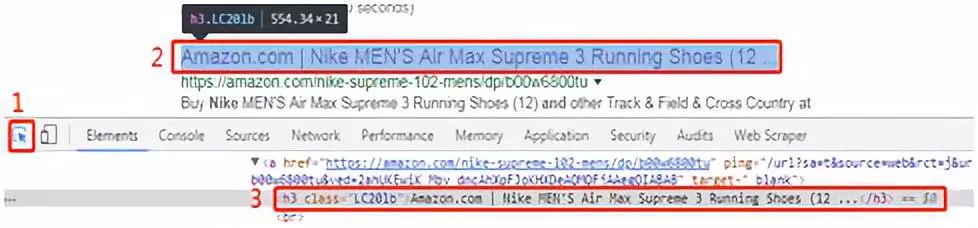
在第三步上点击鼠标右键→「Copy」→「Copy XPath」
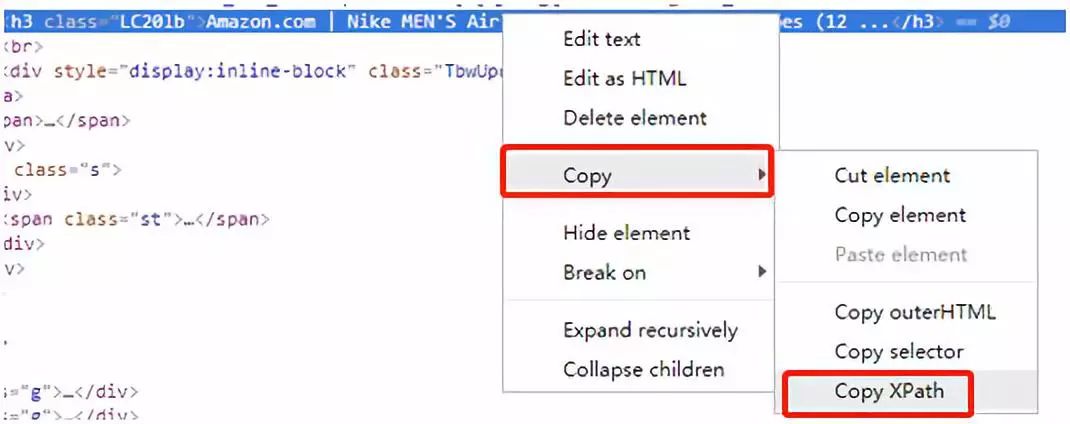
这里要科普一下,「XPath」是XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。使用XPath我们可以准确定位页面中某个元素的位置。
多拷贝几个搜索结果的XPath,可以找出其中的规律:

可见只需将XPath略微修改即可准确定位每个搜索结果的标题,那我们就可以继续敲代码了。
首先查找所有的class为rc的<div>标签,并计算其长度。
all_rc = driver.find_elements_by_xpath("//div[@class='rc']") # 查找所有的class为rc的<div>标签
len_all_rc = len(all_rc) # len()可计算其长度
根据所有的class为rc的<div>标签的长度,生成新的XPath并定位、点击,即跳转至亚马逊商品页面。
# for X in range () 是前开后闭,所以需要len_all_rc + 1 才能循环len_all_rc次。for i in range(1, len_all_rc + 1):
# 拼接新的XPath
xpath = "//*[@id='rso']/div/div/div["+str(i)+"]/div/div/h3/a"
# 根据XPath定位搜索结果的标题,并点击
driver.find_element_by_xpath(xpath).click()
返回亚马逊商品页面源码。
pageSource = driver.page_source如果“Currently unavailable.”在页面源码中,即可确定是为僵尸链接。则在控制台打印该商品链接。
if 'Currently unavailable.' in pageSource:
print(driver.current_url)
完成一次循环后,需要退回到Google搜索界面,下次一循环才能正确进行。
driver.back()完成一页搜索结果筛选后,需要点击搜索结果页面的下一页继续筛选,直到无新的搜索结果为止。
# 定位下一页的按钮next_button = driver.find_element_by_xpath('//*[@id="pnnext"]/span[2]')
# 如果下一页按钮存在if next_button:
# 这定位下一页按钮并点击
driver.find_element_by_xpath('//*[@id="pnnext"]/span[2]').click()
# 否则退出循环、结束程序。
else:
break
▲
以上便是使用「Selenium」+「Chromedriver」从环境搭建、查找链接原理到代码编写来实现爬取僵尸链接的全部过程。其完整代码为:
from selenium import webdriver
url = 'https://www.google.com/search?q=site%EF%BC%9Aamazon.com+Nike+Currently+unavailable.'
driver = webdriver.Chrome('C:Program Files (x86)GoogleChromeApplicationchromedriver.exe')
driver.maximize_window()
driver.get(url)
while True:
all_rc = driver.find_elements_by_xpath("//div[@class='rc']")
len_all_rc = len(all_rc)
for i in range(1, len_all_rc + 1):
xpath = "//*[@id='rso']/div/div/div["+str(i)+"]/div/div/h3/a"
driver.find_element_by_xpath(xpath).click()
pageSource = driver.page_source
if 'Currently unavailable.' in pageSource:
print(driver.current_url)
driver.back()
next_button = driver.find_element_by_xpath('//*[@id="pnnext"]/span[2]')
if next_button:
driver.find_element_by_xpath('//*[@id="pnnext"]/span[2]').click()
else:
break
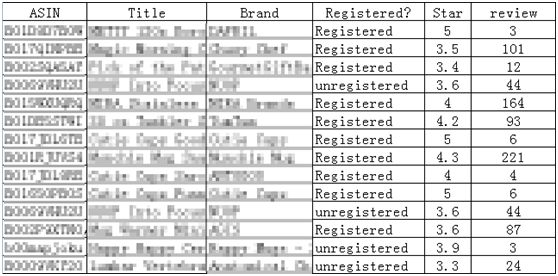
我的这篇文章只是简单的介绍了selenium + webdriver的使用,当然你也可以结合「Requests」+「bs4」爬取每个僵尸链接对应商品的Asin、标题、品牌、star、review等,并保存到文件中方便筛选你中意的僵尸。
如图:
End
【物流福利】













